The StatsTest Flow: Relationship >> Two Continuous >> No Covariates
Not sure this is the right statistical method? Use the Choose Your StatsTest workflow to select the right method.
What is Pearson Correlation?
Pearson Correlation is used to understand the strength of the relationship between two variables. Your variables of interest should be continuous, be normally distributed, be linearly related, and be outlier free. In addition, your variables should have a similar spread across their individual ranges. See more below.
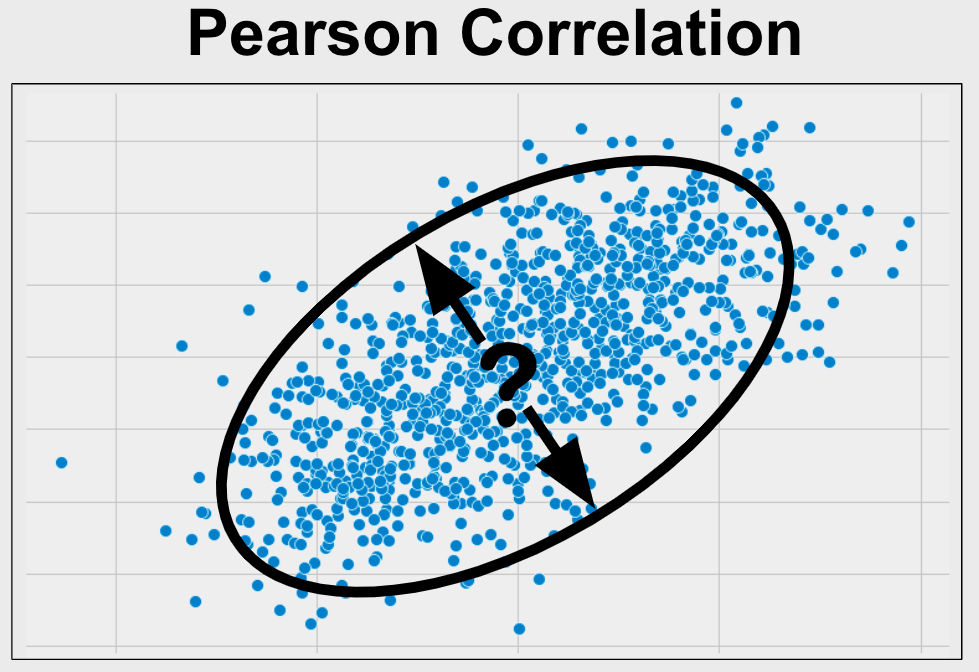
Pearson Correlation is also called Pearson’s r, the Pearson product-moment correlation coefficient and bivariate correlation.
Assumptions for Pearson Correlation
Every statistical method has assumptions. Assumptions mean that your data must satisfy certain properties in order for statistical method results to be accurate.
The assumptions for Pearson Correlation include:
- Continuous
- Normally Distributed
- Linearity
- No Outliers
- Similar Spread Across Range
Let’s dive in to each one of these separately.
Continuous
The variable that you care about (and want to see if it is different between the two groups) must be continuous. Continuous means that the variable can take on any reasonable value.
Some good examples of continuous variables include age, weight, height, test scores, survey scores, yearly salary, etc.
If your variables of interest are categorical, you should use the Phi Coefficient or Cramer’s V instead. If one of your variables is continuous and the other is binary, you should use Point Biserial. If your variables are ordinal, you should use Spearman’s Rho or Kendall’s Tau.
Normally Distributed
The variable that you care about must be spread out in a normal way. In statistics, this is called being normally distributed (aka it must look like a bell curve when you graph the data). Only use an independent samples t-test with your data if the variable you care about is normally distributed.
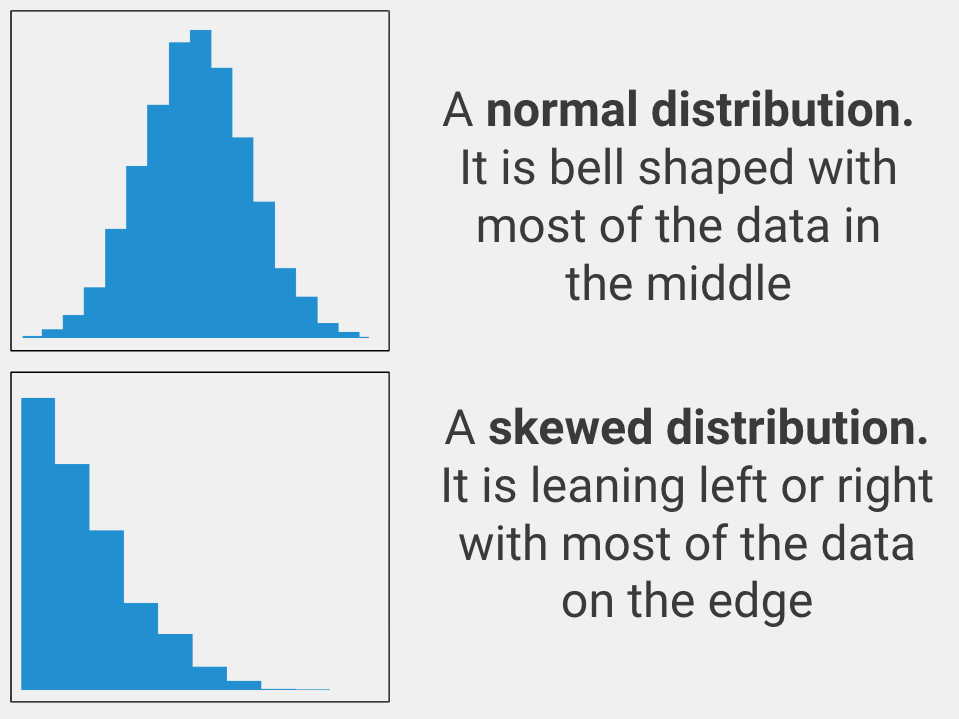
If your variable is not normally distributed, you should use Spearman’s Rho or Kendall’s Tau instead.
Linearity
The variables that you care about must be related linearly. This means that if you plot the variables, you will be able to draw a straight line that fits the shape of the data.
If you do not have linear variables then you should use Spearman’s Rho or Kendall’s Tau instead.
No Outliers
The variables that you care about must not contain outliers. Pearson’s correlation is sensitive to outliers, or data points that have unusually large or small values. You can tell if your variables have outliers by plotting them and observing if any points are far from all other points.
If your variables do have outliers, you can remove them and use Pearson’s correlation or leave them in and use Spearman’s Rho or Kendall’s Tau instead.
Similar Spread Across Range
In statistics this is called homoscedasticity, or making sure the variables have a similar spread across their ranges.
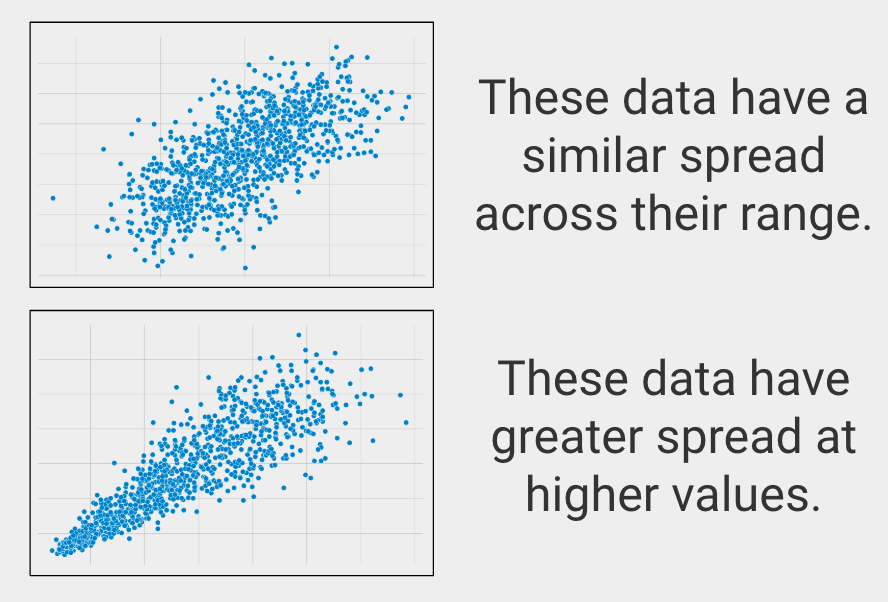
If your groups have a substantially different spread on your variable of interest, then you should use Spearman’s Rho or Kendall’s Tau instead.
When to use Pearson Correlation?
You should use Pearson Correlation in the following scenario:
- You want to know the relationship between two variables
- Your variables of interest are continuous
- You have no covariates
Let’s clarify these to help you know when to use Pearson Correlation
Relationship
You are looking for a statistical test to look at how two variables are related. Other types of analyses include testing for a difference between two variables or predicting one variable using another variable (prediction).
Continuous Data
Your variable of interest must be continuous. Continuous means that your variable of interest can basically take on any value, such as heart rate, height, weight, number of ice cream bars you can eat in 1 minute, etc.
Types of data that are NOT continuous include ordered data (such as finishing place in a race, best business rankings, etc.), categorical data (gender, eye color, race, etc.), or binary data (purchased the product or not, has the disease or not, etc.).
Two Groups
Pearson Correlation can only be used to compare two groups on your variable of interest.
If you have three or more groups, you could considering clustering methods instead.
No Covariates
A covariate is a variable whose effects you want to remove when examining the variable relationship of interest. For instance, if you’re examining the relationship between age and memory performance, you may be interested in removing the effects of education level. This way, you can be sure that education level isn’t influencing the results.
If you do have one or more covariates, you should use Partial Correlation instead.
Pearson Correlation Example
Variable 1: Height.
Variable 2: Weight.
In this example, we are interested in the relationship between height and weight. To begin, we collect height and weight measurements from a group of people.
Before running Pearson Correlation, we check that our variables meet the assumptions of the method. After confirming that our variables are normally distributed, have no outliers, and are linearly related (see above for details), we move forward with the analysis.
The analysis will result in a correlation coefficient (called “r”) and a p-value. R values range from -1 to 1. A negative value of r indicates that the variables are inversely related, or when one variable increases, the other decreases. On the other hand, positive values indicate that when one variable increases, so does the other.
The p-value represents the chance of seeing our results if there was no actual relationship between our variables. A p-value less than or equal to 0.05 means that our result is statistically significant and we can trust that the difference is not due to chance alone.
Frequently Asked Questions
Q: How do I run Pearson Correlation in SPSS or R?
A: StatsTest is focused on helping you pick the right statistical method every time. There are many resources available to help you figure out how to run this method with your data:
SPSS article: https://researchbasics.education.uconn.edu/instructions-for-using-spss-to-calculate-pearsons-r/
SPSS video: https://www.youtube.com/watch?v=VOI5IlHfZVE
R article: http://www.sthda.com/english/wiki/correlation-test-between-two-variables-in-r
R video: https://www.youtube.com/watch?v=uESm0FoDDgM
Help!
If you still can’t figure something out, feel free to reach out.