The StatsTest Flow: Prediction >> Ordered Categorical Dependent Variable
Not sure this is the right statistical method? Use the Choose Your StatsTest workflow to select the right method.
What is Ordinal Logistic Regression?
Ordinal Logistic Regression is a statistical test used to predict a single ordered categorical variable using one or more other variables. It also is used to determine the numerical relationship between such sets of variables. The variable you want to predict should be ordinal and your data should meet the other assumptions listed below.
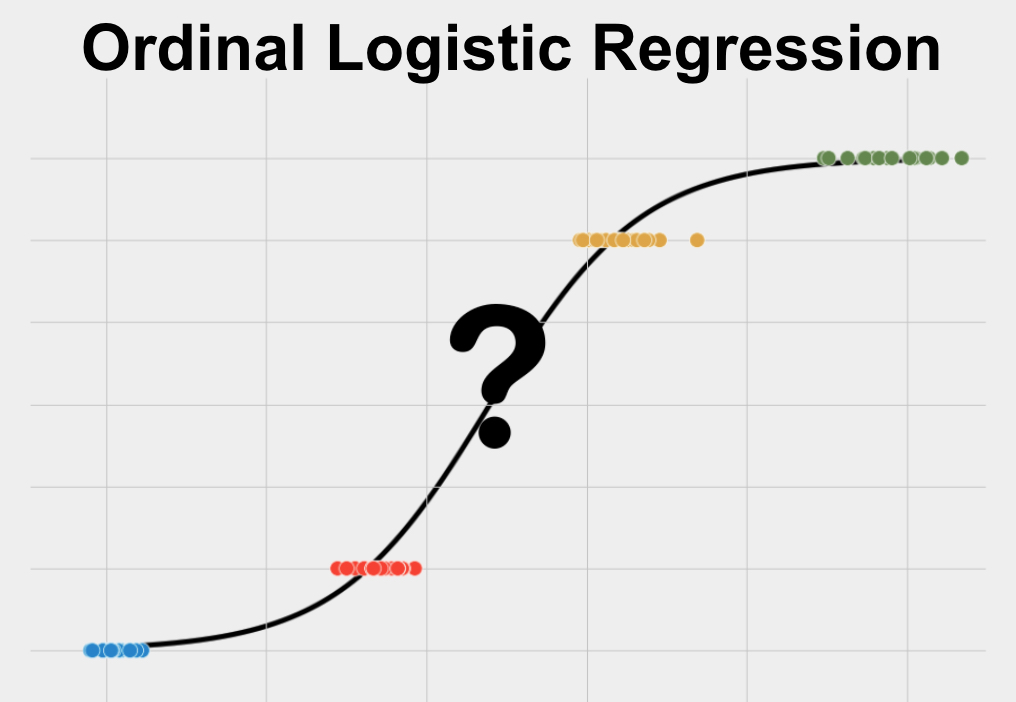
Ordinal Logistic Regression is sometimes also called ordered categorical logistic regression, the ordered logit, and ordinal regression.
Assumptions for Ordinal Logistic Regression
Every statistical method has assumptions. Assumptions mean that your data must satisfy certain properties in order for statistical method results to be accurate.
The assumptions for Ordinal Logistic Regression include:
- Linearity
- No Outliers
- Independence
- No Multicollinearity
Let’s dive in to each one of these separately.
Linearity
Logistic regression fits a logistic curve to binary data. This logistic curve can be interpreted as the probability associated with each outcome across independent variable values. Logistic regression assumes that the relationship between the natural log of these probabilities (when expressed as odds) and your predictor variable is linear.
No Outliers
The variables that you care about must not contain outliers. Logistic Regression is sensitive to outliers, or data points that have unusually large or small values. You can tell if your variables have outliers by plotting them and observing if any points are far from all other points.
Independence
Each of your observations (data points) should be independent. This means that each value of your variables doesn’t “depend” on any of the others. For example, this assumption is usually violated when there are multiple data points over time from the same unit of observation (e.g. subject/participant/customer/store), because the data points from the same unit of observation are likely to be related or affect one another.
No Multicollinearity
Multicollinearity refers to the scenario when two or more of the independent variables are substantially correlated amongst each other. When multicollinearity is present, the regression coefficients and statistical significance become unstable and less trustworthy, though it doesn’t affect how well the model fits the data per se.
When to use Ordinal Logistic Regression?
You should use Ordinal Logistic Regression in the following scenario:
- You want to use one variable in a prediction of another, or you want to quantify the numerical relationship between two variables
- The variable you want to predict (your dependent variable) is an ordered categorical (ordinal) variable
Let’s clarify these to help you know when to use Ordinal Logistic Regression
Prediction
You are looking for a statistical test to predict one variable using another. This is a prediction question. Other types of analyses include examining the strength of the relationship between two variables (correlation) or examining differences between groups (difference).
Ordered Categorical Dependent Variable
Ordered categorical variables (aka ordinal variables) have categories that fit into a natural order. Example of ordinal variables are finishing place in a race, business rankings, and income brackets (high, medium, low)
Types of data that are NOT ordinal include: categorical without order (eye color, city of residence, type of dog, etc) binary data (true/false, purchased the product or not, etc), or continuous data (height, income, etc).
If your dependent variable is continuous, you should use Simple Linear Regression, and if your dependent variable is binary, then you should use Simple Logistic Regression.
Ordinal Logistic Regression Example
Dependent Variable: Type of premium membership purchased (e.g. gold, platinum, diamond)
Independent Variable: Consumer income
The null hypothesis, which is statistical lingo for what would happen if the treatment does nothing, is that there is no relationship between consumer income and the type of premium membership purchased. Our test will assess the likelihood of this hypothesis being true.
We gather our data and after assuring that the assumptions of multinomial logistic regression are met, we perform the analysis.
When we run this analysis, we get coefficients for each term in the model. These coefficients can be used to determine the predicted numerical relationship between consumer income and the probability of each consumer selecting a particular type of premium membership.
P-values can be determined using the coefficients and their standard errors. These p-values represent the chance of seeing our results assuming there is actually no relationship between consumer income and the type of premium membership purchased. A p-value less than or equal to 0.05 means that our result is statistically significant and we can trust that the difference is not due to chance alone.
Frequently Asked Questions
Q: How do I run Ordinal Logistic Regression in SPSS, R, SAS, or STATA?
A: This resource is focused on helping you pick the right statistical method every time. There are many resources available to help you figure out how to run this method with your data:
SPSS article: http://www.restore.ac.uk/srme/www/fac/soc/wie/research-new/srme/modules/mod5/4/index.html
SPSS video: https://www.youtube.com/watch?v=rSCdwZD1DuM
R article: https://www.r-bloggers.com/how-to-perform-ordinal-logistic-regression-in-r/
R video: https://www.youtube.com/watch?v=qkivJzjyHoA
Help!
If you still can’t figure something out, feel free to reach out.