The StatsTest Flow: Prediction >> Continuous Dependent Variable >> More than One Independent Variable >> No Repeated Measures >> One Dependent Variable
Not sure this is the right statistical method? Use the Choose Your StatsTest workflow to select the right method.
What is Multiple Linear Regression?
Multiple Linear Regression is a statistical test used to predict a single variable using two or more other variables. It also is used to determine the numerical relationship between one variable and others. The variable you want to predict should be continuous and your data should meet the other assumptions listed below.
Assumptions for Multiple Linear Regression
Every statistical method has assumptions. Assumptions mean that your data must satisfy certain properties in order for statistical method results to be accurate.
The assumptions for Multiple Linear Regression include:
- Linearity
- No Outliers
- Similar Spread across Range
- Independence
- Normality of Residuals
- No Multicollinearity
Let’s dive in to each one of these separately.
Linearity
The variables that you care about must be related linearly. This means that if you plot the variables, you will be able to draw a straight line that fits the shape of the data.
No Outliers
The variables that you care about must not contain outliers. Linear Regression is sensitive to outliers, or data points that have unusually large or small values. You can tell if your variables have outliers by plotting them and observing if any points are far from all other points.
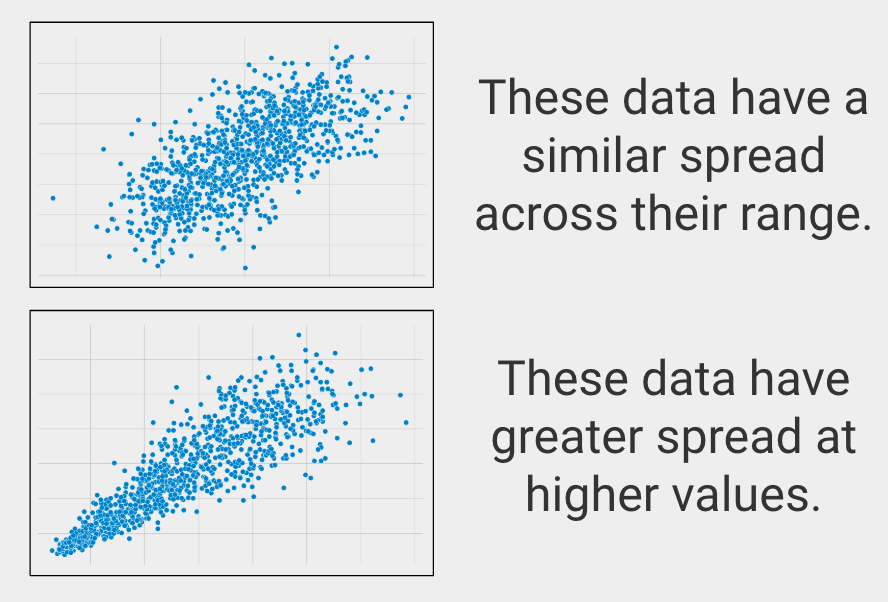
Similar Spread across Range
In statistics this is called homoscedasticity, which describes when variables have a similar spread across their ranges.
Independence
Each of your observations (data points) should be independent. This means that each value of your variables doesn’t “depend” on any of the others. For example, this assumption is usually violated when there are multiple data points over time from the same unit of observation (e.g. subject/participant/customer/store), because the data points from the same unit of observation are likely to be related or affect one another.
If your data have repeated measures over time from the same units of observation, you should use a Mixed Effects Model.
Normality of Residuals
The word “residuals” refers to the values resulting from subtracting the expected (or predicted) dependent variables from the actual values. The distribution of these values should match a normal (or bell curve) distribution shape.
Meeting this assumption assures that the results of the regression are equally applicable across the full spread of the data and that there is no systematic bias in the prediction.
No Multicollinearity
Multicollinearity refers to the scenario when two or more of the independent variables are substantially correlated amongst each other. When multicollinearity is present, the regression coefficients and statistical significance become unstable and less trustworthy, though it doesn’t affect how well the model fits the data per se.
When to use Multiple Linear Regression?
You should use Multiple Linear Regression in the following scenario:
- You want to use one variable in a prediction of another, or you want to quantify the numerical relationship between two variables
- The variable you want to predict (your dependent variable) is continuous
- You have more than one independent variable, or one variable that you are using as a predictor
- You have no repeated measures from the same unit of observation
- You have one dependent variable
Let’s clarify these to help you know when to use Multiple Linear Regression
Prediction
You are looking for a statistical test to predict one variable using another. This is a prediction question. Other types of analyses include examining the strength of the relationship between two variables (correlation) or examining differences between groups (difference).
Continuous Dependent Variable
The variable you want to predict must be continuous. Continuous means that your variable of interest can basically take on any value, such as heart rate, height, weight, number of ice cream bars you can eat in 1 minute, etc.
Types of data that are NOT continuous include ordered data (such as finishing place in a race, best business rankings, etc.), categorical data (gender, eye color, race, etc.), or binary data (purchased the product or not, has the disease or not, etc.).
If your dependent variable is binary, you should use Multiple Logistic Regression, and if your dependent variable is categorical, then you should use Multinomial Logistic Regression or Linear Discriminant Analysis.
More than One Independent Variable
Multiple Linear Regression is used when there is two or more predictor variables measured at a single point in time.
No Repeated Measures
This method is suited for the scenario when there is only one observation for each unit of observation. The unit of observation is what composes a “data point”, for example, a store, a customer, a city, etc…
If you have one or more independent variables but they are measured for the same group at multiple points in time, then you should use a Mixed Effects Model.
One Dependent Variable
To run multiple linear regression, you should have only one dependent variable, or variable that you are trying to predict.
If you have more than one variable you are trying to predict at the same time, you should use Multivariate Multiple Linear Regression.
Multiple Linear Regression Example
Dependent Variable: Revenue
Independent Variable 1: Dollars spent on advertising by city
Independent Variable 2: City Population
The null hypothesis, which is statistical lingo for what would happen if the treatment does nothing, is that there is no relationship between spend on advertising and the advertising dollars or population by city. Our test will assess the likelihood of this hypothesis being true.
We gather our data and after assuring that the assumptions of linear regression are met, we perform the analysis.
When we run this analysis, we get beta coefficients and p-values for each term in the model. For any linear regression model, you will have one beta coefficient that equals the intercept of your linear regression line (often labelled with a 0 as β0). This is simply where the regression line crosses the y-axis. In the case of multiple linear regression, there are additionally two more more other beta coefficients (β1, β2, etc), which represent the relationship between the independent and dependent variables.
These additional beta coefficients are the key to understanding the numerical relationship between your variables. Essentially, for each unit (value of 1) increase in a given independent variable, your dependent variable is expected to change by the value of the beta coefficient associated with that independent variable (while holding other independent variables constant).
The p-value associated with these additional beta values is the chance of seeing our results assuming there is actually no relationship between that variable and revenue. A p-value less than or equal to 0.05 means that our result is statistically significant and we can trust that the difference is not due to chance alone.
In addition, this analysis will result in an R-Squared (R2) value. This value can range from 0-1 and represents how well your linear regression line fits your data points. The higher the R2, the better your model fits your data.
Frequently Asked Questions
Q: How do I run Multiple Linear Regression in SPSS, R, SAS, or STATA?
A: This resource is focused on helping you pick the right statistical method every time. There are many resources available to help you figure out how to run this method with your data:
SPSS article: https://statistics.laerd.com/spss-tutorials/linear-regression-using-spss-statistics.php
SPSS video: https://www.youtube.com/watch?v=rig4ZZ_cBZo
R article: https://www.statmethods.net/stats/regression.html
R video: https://www.youtube.com/watch?v=q1RD5ECsSB0
Help!
If you still can’t figure something out, feel free to reach out.