The StatsTest Flow: Difference >> Continuous Variable of Interest >> Two Sample Tests (2 groups) >> Paired Samples >> Normal Variable of Interest
Not sure this is the right statistical method? Use the Choose Your StatsTest workflow to select the right method.
What is a Paired Samples T-Test?
The Paired Samples T-Test is a statistical test used to determine if 2 paired groups are significantly different from each other on your variable of interest. Your variable of interest should be continuous, be normally distributed, and have a similar spread between your 2 groups. Your 2 groups should be paired (often two observations from the same group) and you should have enough data (more than 5 values in each group).
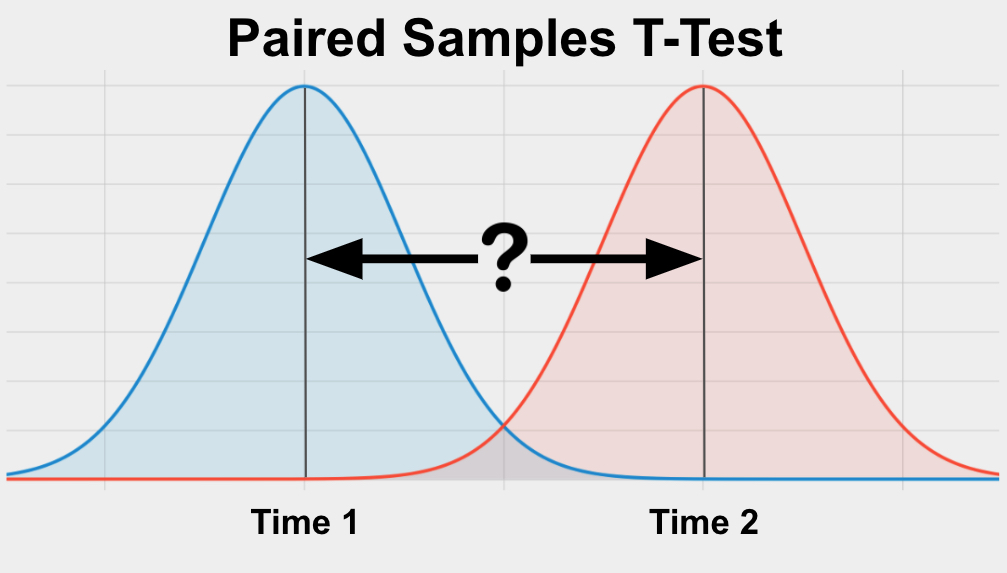
The Paired Samples T-Test is also called the Paired Sample T-Test, Dependent Sample T-Test and the Paired T-Test.
Assumptions for a Paired Samples T-Test
Every statistical method has assumptions. Assumptions mean that your data must satisfy certain properties in order for statistical method results to be accurate.
The assumptions for the Paired Samples T-Test include:
- Continuous
- Normally Distributed
- Random Sample
- Enough Data
- Similar Spread Between Groups
Let’s dive in to each one of these separately.
Continuous
The variable that you care about (and want to see if it is different between the two groups) must be continuous. Continuous means that the variable can take on any reasonable value.
Some good examples of continuous variables include age, weight, height, test scores, survey scores, yearly salary, etc.
If the variable that you care about is a proportion (48% of males voted vs 56% of females voted) then you should probably use the McNemar Test instead.
Normally Distributed
The variable that you care about must be spread out in a normal way. In statistics, this is called being normally distributed (aka it must look like a bell curve when you graph the data). Only use an paired samples t-test with your data if the variable you care about is normally distributed.
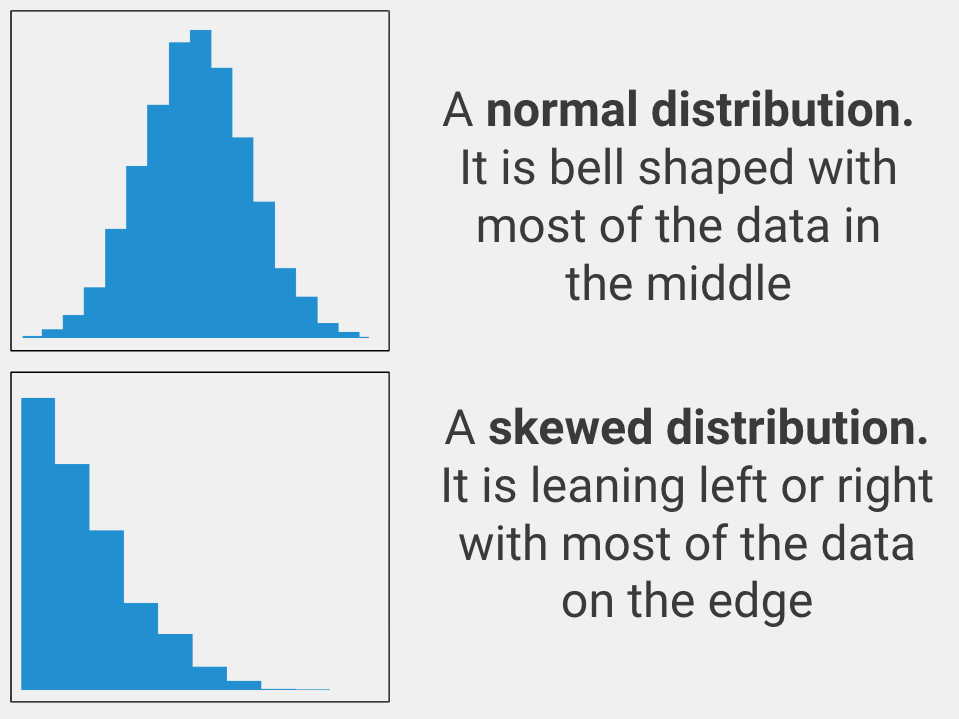
If your variable is not normally distributed, you should use the Wilcoxon Signed-Rank Test instead.
Random Sample
The data points for each group in your analysis must have come from a simple random sample. This means that if you wanted to see if drinking sugary soda makes you gain weight, you would need to randomly select a group of soda drinkers for your soda drinker group, and then randomly select a group of non-soda drinkers for your non-soda drinking group.
The key here is that the data points for each group were randomly selected. This is important because if your groups were not randomly determined then your analysis will be incorrect. In statistical terms this is called bias, or a tendency to have incorrect results because of bad data.
If you do not have a random sample, the conclusions you can draw from your results are very limited. You should try to get a simple random sample. If your two samples are not paired (2 measurements from two different groups of subjects) then you should use an Independent Samples T-Test instead.
Enough Data
The sample size (or data set size) should be greater than 5 in each group. Some people argue for more, but more than 5 is probably sufficient.
The sample size also depends on the expected size of the difference between groups. If you expect a large difference between groups, then you can get away with a smaller sample size. If you expect a small difference between groups, then you likely need a larger sample.
If your sample size is greater than 30 (and you know the average and spread of the population), you should run a Paired Samples Z-Test instead.
Similar Spread Between Groups
In statistics this is called homogeneity of variance, or making sure the variable of interest is spread similarly between the two groups (see image below).

When to use a Paired Samples T-Test?
You should use a Paired Samples T-Test in the following scenario:
- You want to know if two measurements from a group are different on your variable of interest
- Your variable of interest is continuous
- You have two and only two groups (i.e. two measurements from a single group)
- You have paired samples
- You have a normal variable of interest
Let’s clarify these to help you know when to use an Paired Samples T-Test.
Difference
You are looking for a statistical test to see whether two groups are significantly different on your variable of interest. This is a difference question. Other types of analyses include examining the relationship between two variables (correlation) or predicting one variable using another variable (prediction).
Continuous Data
Your variable of interest must be continuous. Continuous means that your variable of interest can basically take on any value, such as heart rate, height, weight, number of ice cream bars you can eat in 1 minute, etc.
Types of data that are NOT continuous include ordered data (such as finishing place in a race, best business rankings, etc.), categorical data (gender, eye color, race, etc.), or binary data (purchased the product or not, has the disease or not, etc.).
Two Groups
A Paired Samples T-Test can only be used to compare two groups (i.e. two observations from one group) on your variable of interest.
If you have three or more observations from the same group, you should use a One Way Repeated Measures Anova analysis instead.
Paired Samples
Paired samples means that your two “groups” consist of data from the same group observed at multiple points in time. For example, if you randomly sample men at two points in time to get their IQ score, then the two observations are paired.
If your data consist of two samples from two independent groups, then you should use an Independent Samples T-Test instead.
Normal Variable of Interest
Normality was discussed earlier on this page and simply means your plotted data is bell shaped with most of the data in the middle. If you actually would like to prove that your data is normal, you can use the Kolmogorov-Smirnov test or the Shapiro-Wilk test.
Paired Samples T-Test Example
Observation 1: A group of people were evaluated at baseline.
Observation 2: This same group of people were evaluated after a 12-week exercise program.
Variable of interest: Cholesterol levels.
In this example, we have one group with two observations, meaning that the data are paired.
The null hypothesis, which is statistical lingo for what would happen if the exercise program has no effect, is that there will be no difference in cholesterol levels measured before and after the exercise program. After observing that our data meet the assumptions of a paired samples t-test, we proceed with the analysis.
When we run the analysis, we get a test statistic (in this case a T-statistic) and a p-value.
The test statistic is a measure of how different the group is on our cholesterol variable of interest across the two observations. The p-value is the chance of seeing our results assuming the exercise program actually doesn’t do anything. A p-value less than or equal to 0.05 means that our result is statistically significant and we can trust that the difference is not due to chance alone.
Frequently Asked Questions
Q: How do I run a paired samples t-test in SPSS or R?
A: This resource is focused on helping you pick the right statistical method every time. There are many resources available to help you figure out how to run this method with your data:
SPSS article: https://libguides.library.kent.edu/SPSS/PairedSamplestTest
SPSS video: https://www.youtube.com/watch?v=vII22ZnFOP0
R article: http://www.sthda.com/english/wiki/paired-samples-t-test-in-r
R video: https://www.youtube.com/watch?v=yD6aU0fY2lo
Help!
If you still can’t figure something out, feel free to reach out.