StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.

Practical Bayes: Using PyMC, Stan, and brms for Real Analysis
Hands-on guide to Bayesian tools. Compare PyMC, Stan, and brms with real examples. Learn which tool fits your workflow and how to get started fast.
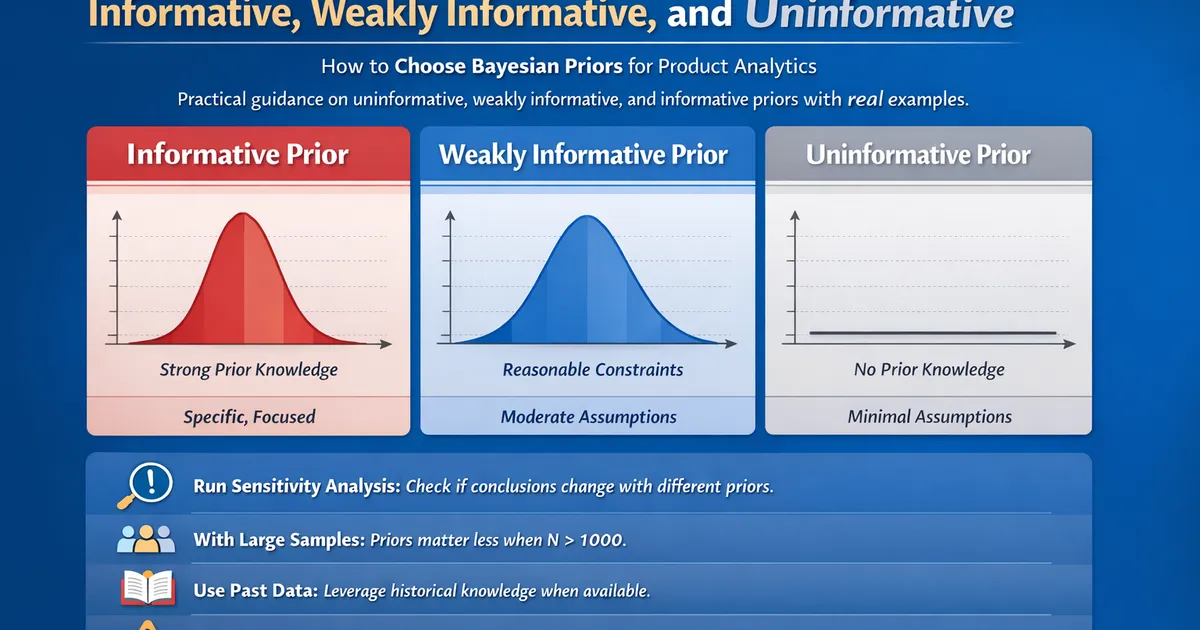
Prior Selection: Informative, Weakly Informative, and Uninformative
How to choose Bayesian priors for product analytics. Practical guidance on uninformative, weakly informative, and informative priors with real examples.
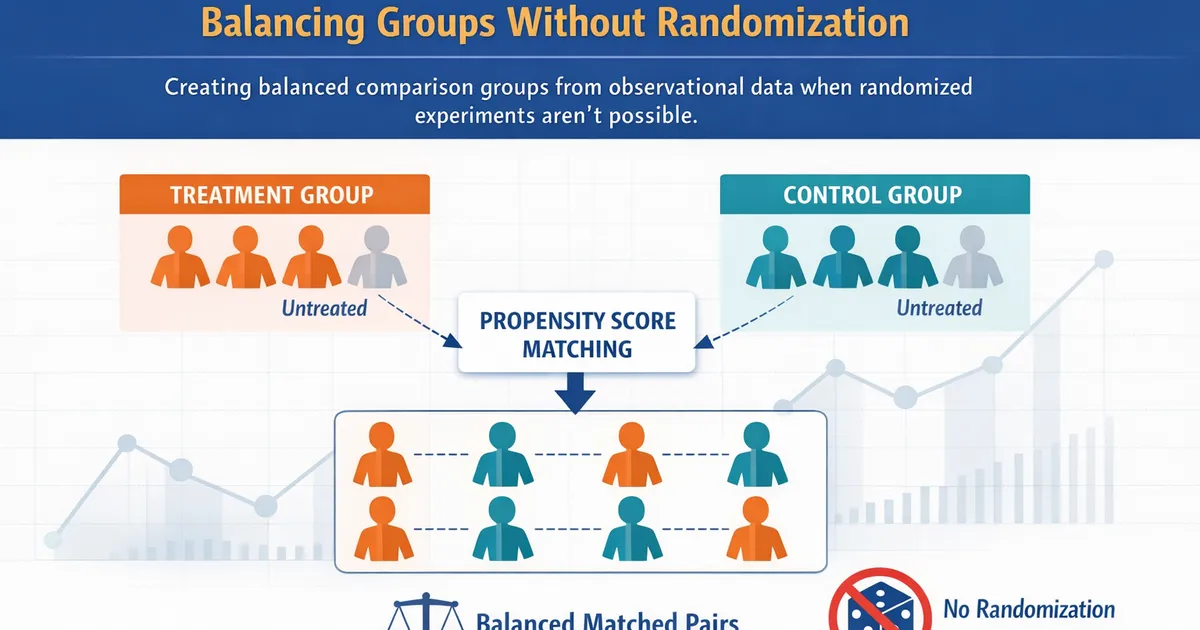
Propensity Score Matching: Balancing Groups Without Randomization
Learn how propensity score matching creates balanced comparison groups from observational data when randomized experiments aren't possible.
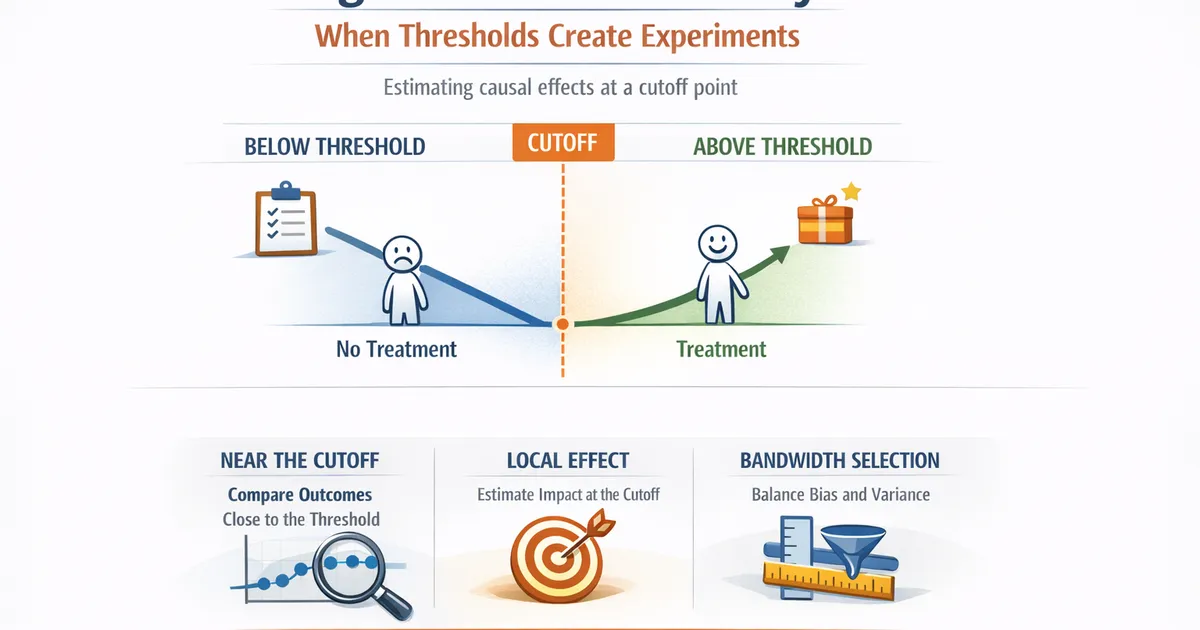
Regression Discontinuity: When Thresholds Create Experiments
How regression discontinuity designs exploit score cutoffs to estimate causal effects. A practical guide for product analysts with real-world examples.
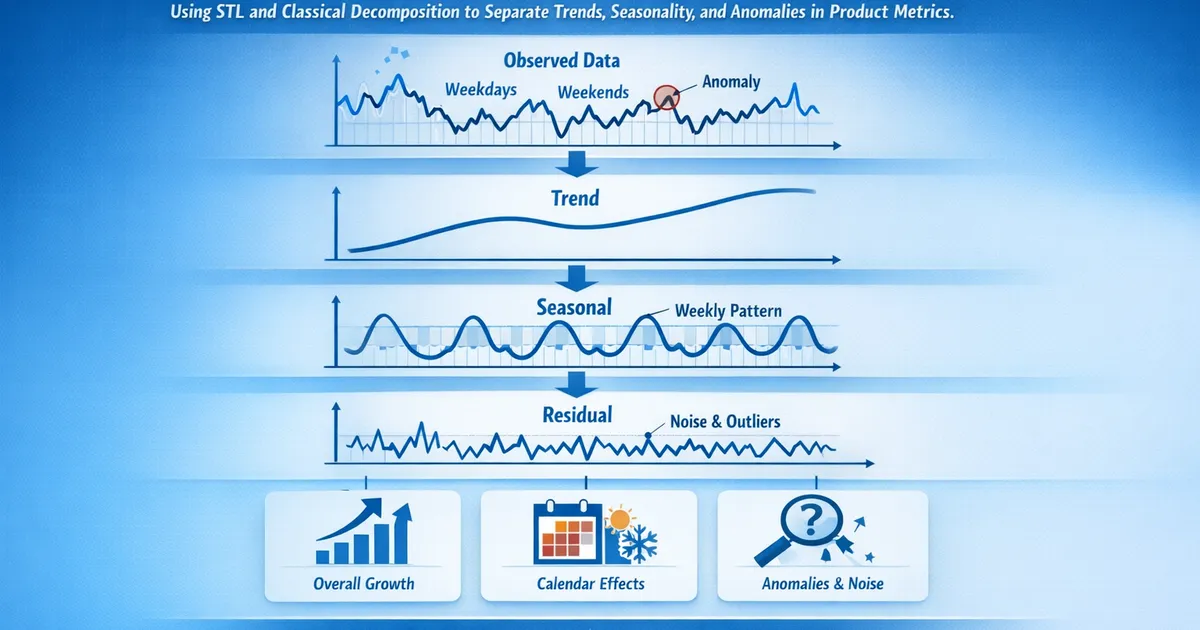
Seasonal Decomposition: Separating Signal from Calendar Effects
How to use STL and classical decomposition to separate trends, seasonality, and anomalies in product metrics.
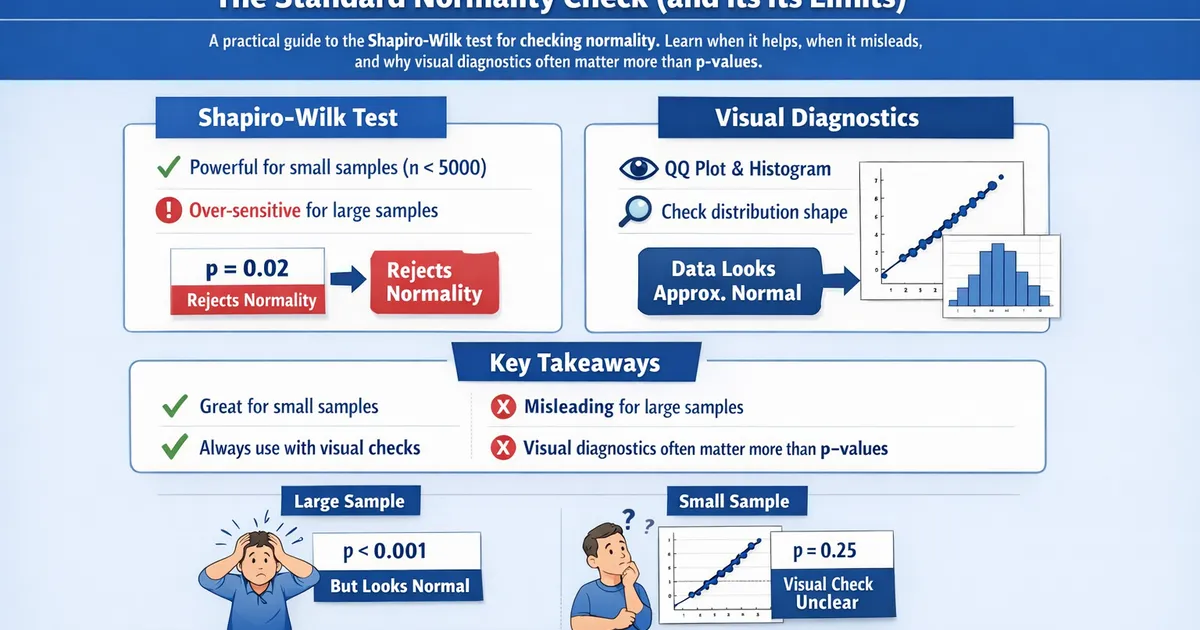
Shapiro-Wilk Test: The Standard Normality Check (and Its Limits)
A practical guide to the Shapiro-Wilk test for checking normality. Learn when it helps, when it misleads, and why visual diagnostics often matter more than p-values.

Synthetic Control: Building a Counterfactual for Geo Tests
How the synthetic control method builds a data-driven counterfactual from donor units to estimate causal effects in geo tests and market-level rollouts.
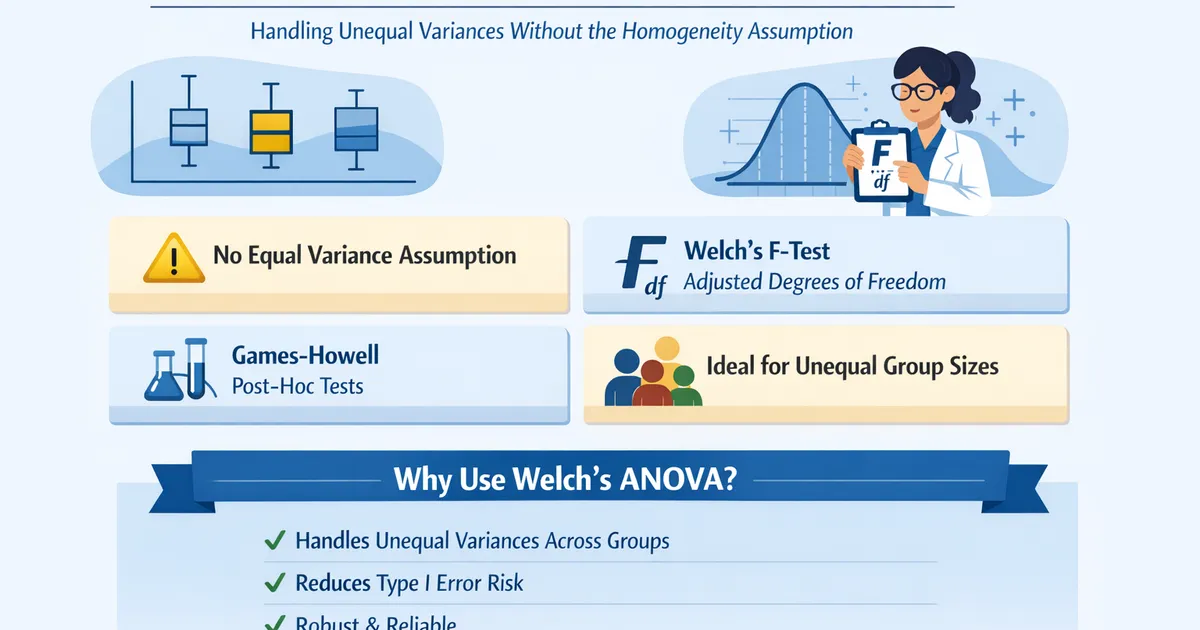
Welch's ANOVA: When Group Variances Differ
Welch's ANOVA handles unequal variances across groups without requiring the homogeneity assumption. Learn when to use it instead of standard one-way ANOVA and how to follow up.
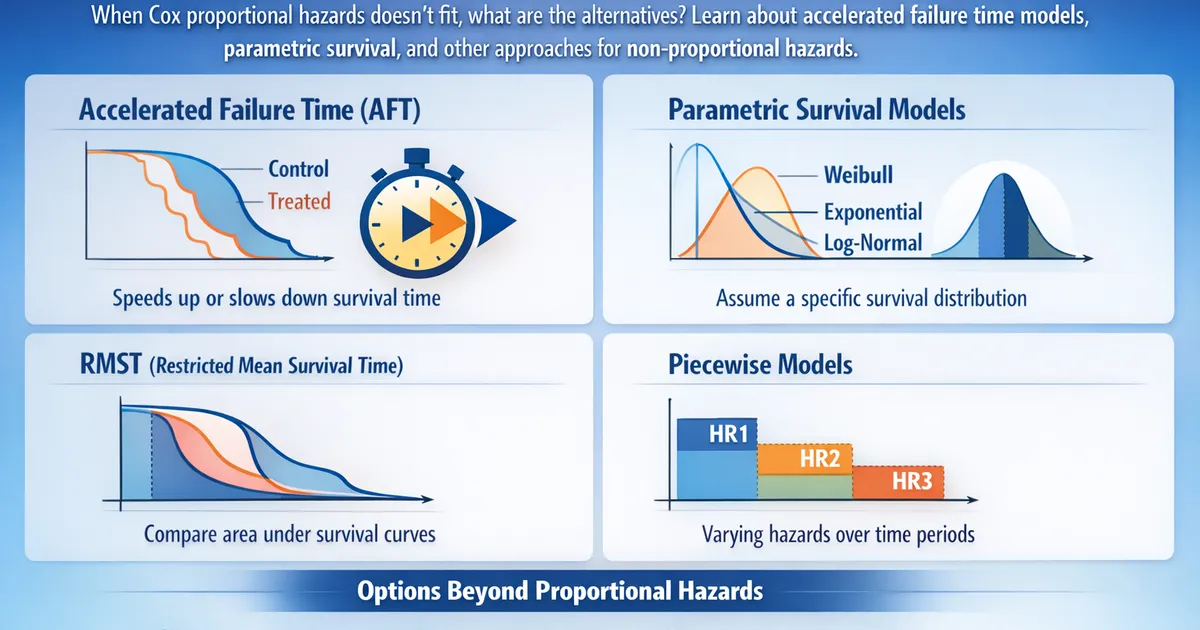
Alternatives to Cox: Accelerated Failure Time and Other Models
When Cox proportional hazards doesn't fit, what are the alternatives? Learn about accelerated failure time models, parametric survival, and other approaches for non-proportional hazards.

Audit Trails: How to Document Assumptions, Data Filters, and Analysis Decisions
Build analysis audit trails that let anyone understand and reproduce your work. Document data filters, exclusions, assumptions, and decision points so future investigations are possible.
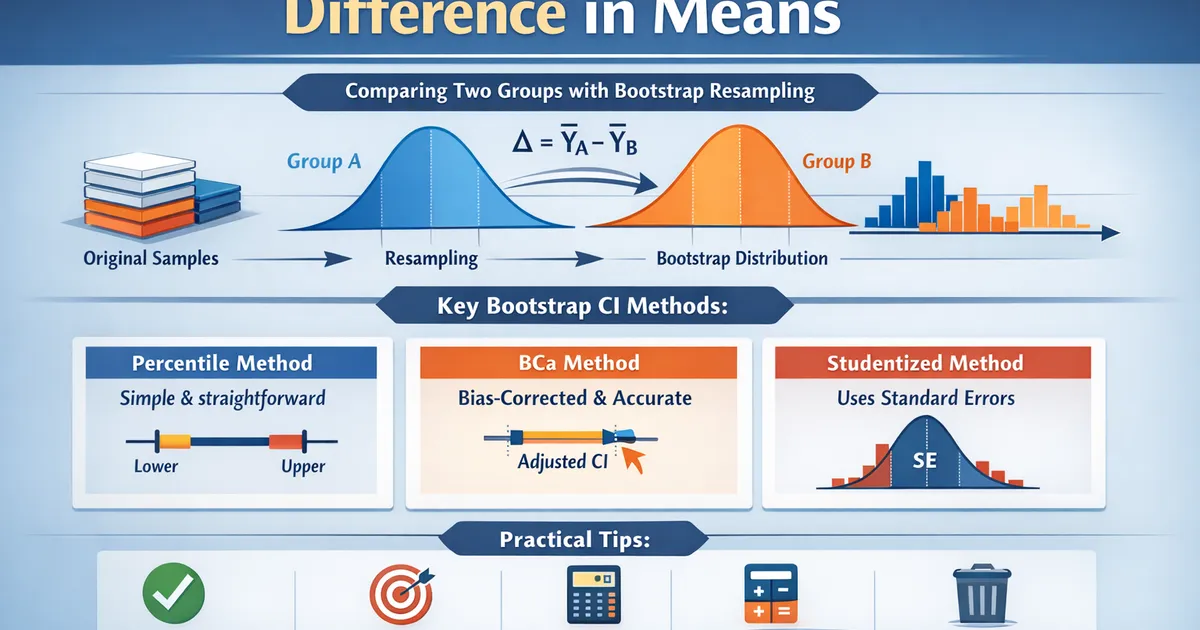
Bootstrap Confidence Intervals for Difference in Means
How to use bootstrap resampling to construct confidence intervals for comparing two groups. Covers percentile, BCa, and studentized methods with practical guidance.
