StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.
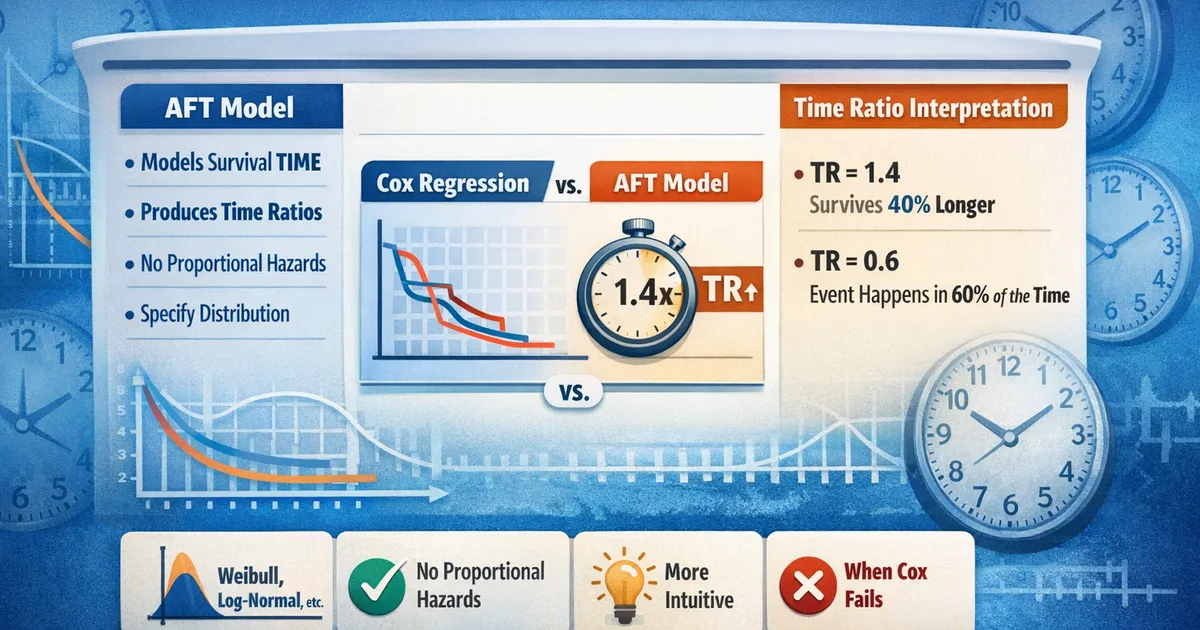
Accelerated Failure Time Models: When Cox Doesn't Fit
When proportional hazards fail, AFT models offer an interpretable alternative. Learn when to use accelerated failure time models, how to interpret time ratios, and how they compare to Cox regression.

Autocorrelation: Why Your Daily Metrics Aren't Independent
Learn why autocorrelation in product metrics invalidates standard tests, how to detect it, and what corrections to apply.

Bayesian A/B Testing: Posterior Probabilities for Ship Decisions
How to run Bayesian A/B tests that give you the probability a variant wins. Practical guide with Python code for conversion rates and revenue metrics.
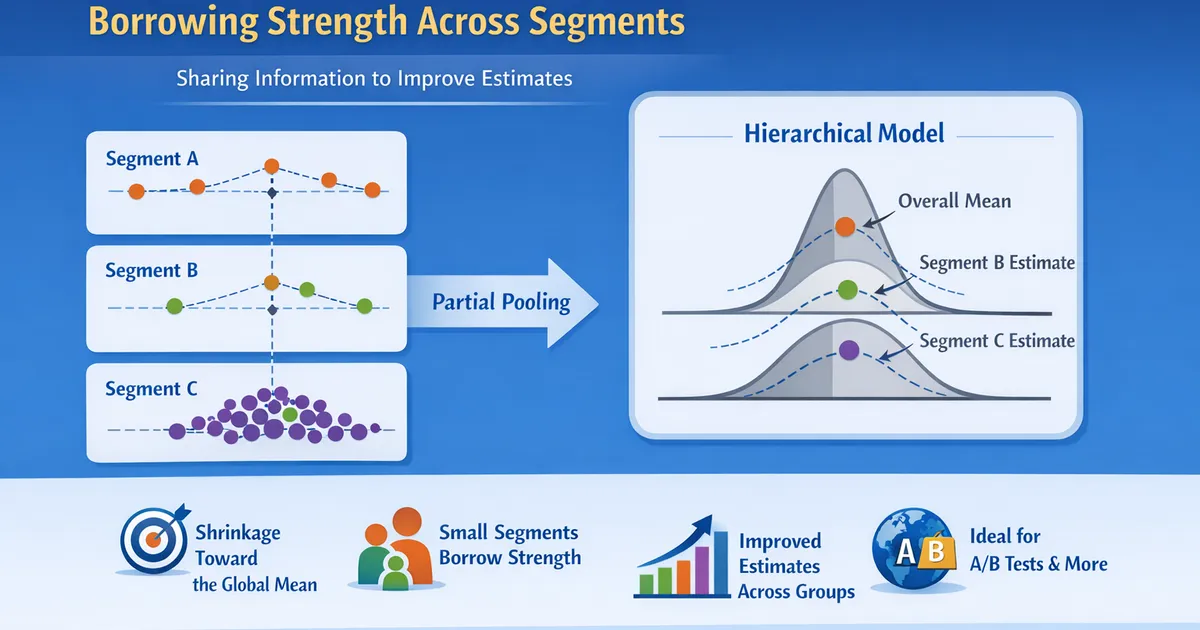
Bayesian Hierarchical Models: Borrowing Strength Across Segments
How hierarchical Bayesian models share information across segments to improve estimates. Learn partial pooling, when it helps, and how to implement it.

Bayesian Regression: When Shrinkage Improves Predictions
Learn how Bayesian regression uses priors as regularization to improve predictions. Practical guide to shrinkage, uncertainty quantification, and when it beats OLS.
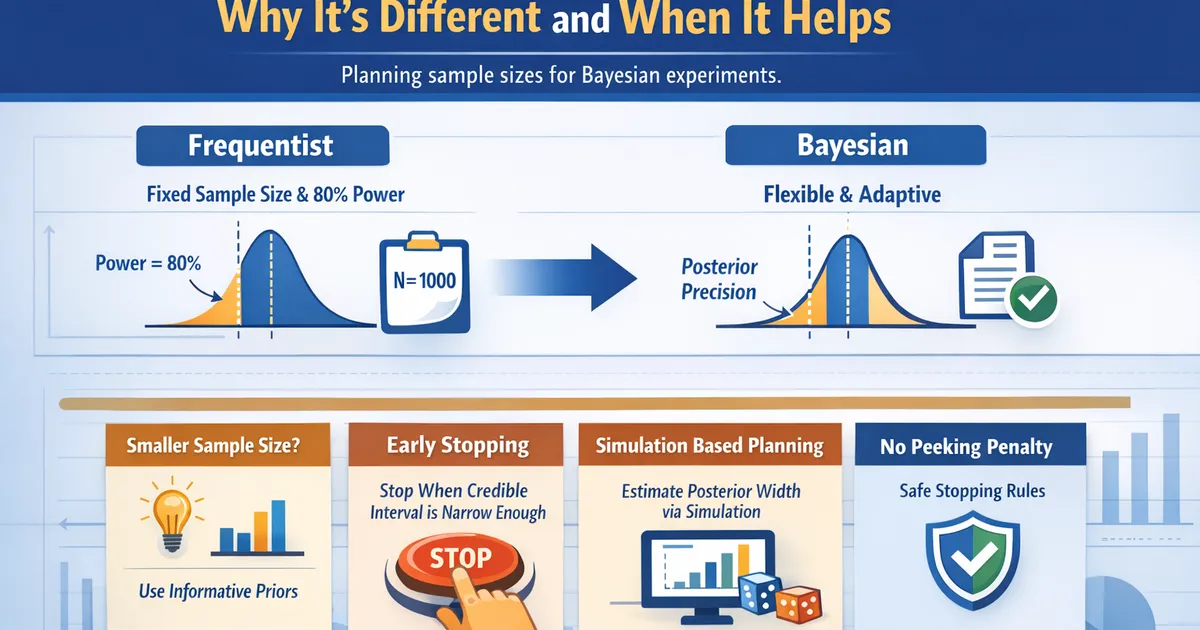
Bayesian Sample Size: Why It's Different and When It Helps
How to plan sample sizes for Bayesian experiments. Learn why Bayesian sample sizing differs from frequentist, and when it gives you smaller or more flexible experiments.
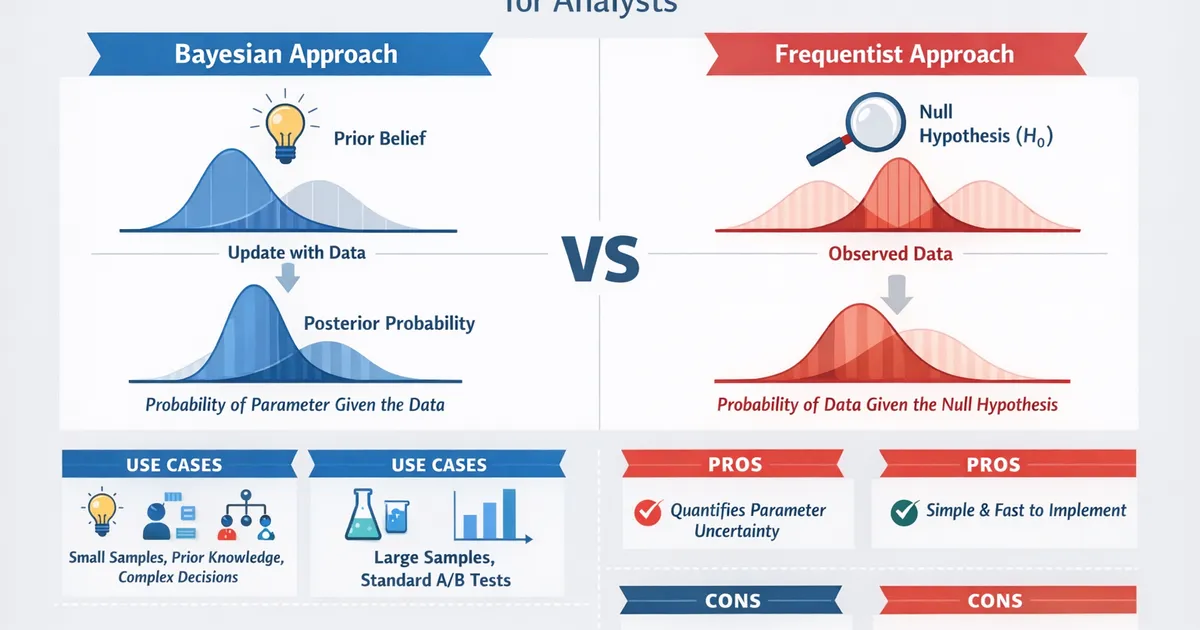
Bayesian vs. Frequentist: A Practical Comparison for Analysts
Side-by-side comparison of Bayesian and frequentist methods for product analysts. Learn which approach fits your problem, team, and decision context.
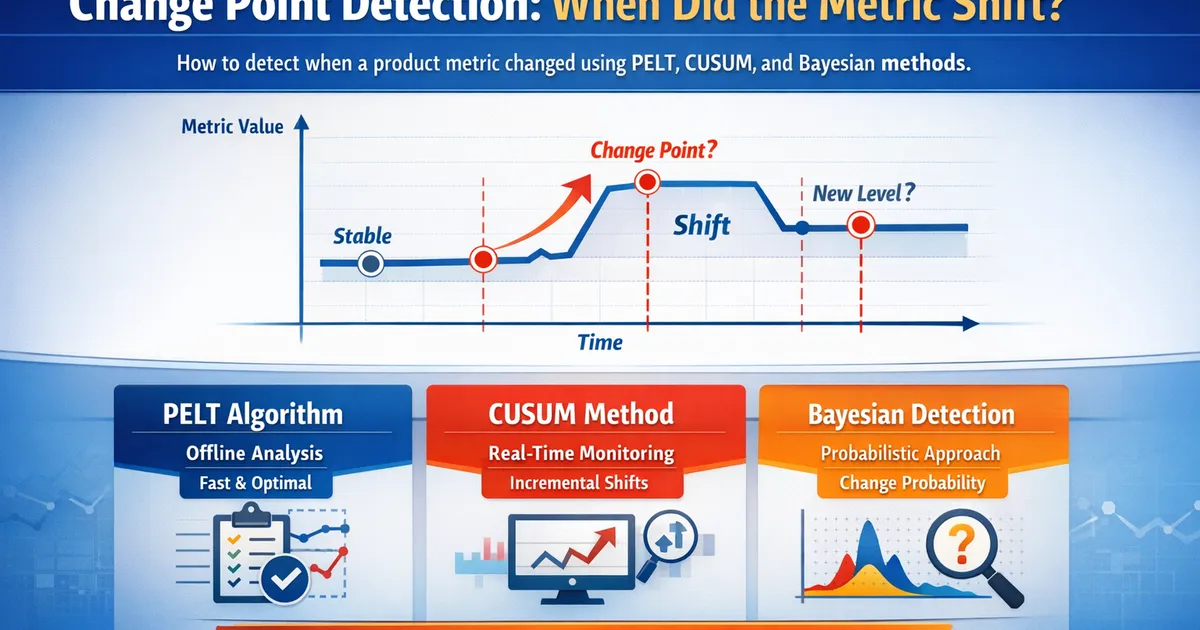
Change Point Detection: When Did the Metric Shift?
How to detect when a product metric changed using PELT, CUSUM, and Bayesian change point detection methods.
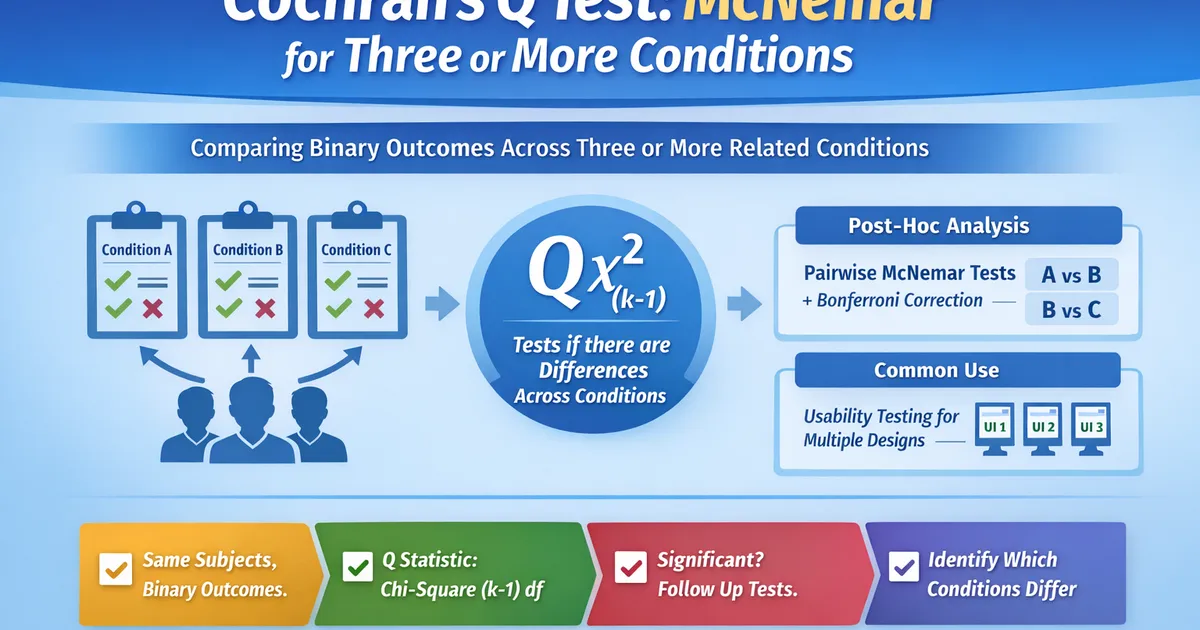
Cochran's Q Test: McNemar for Three or More Conditions
A practical guide to Cochran's Q test for comparing binary outcomes across three or more related conditions. Learn when to use it, how to interpret results, and post-hoc follow-ups.
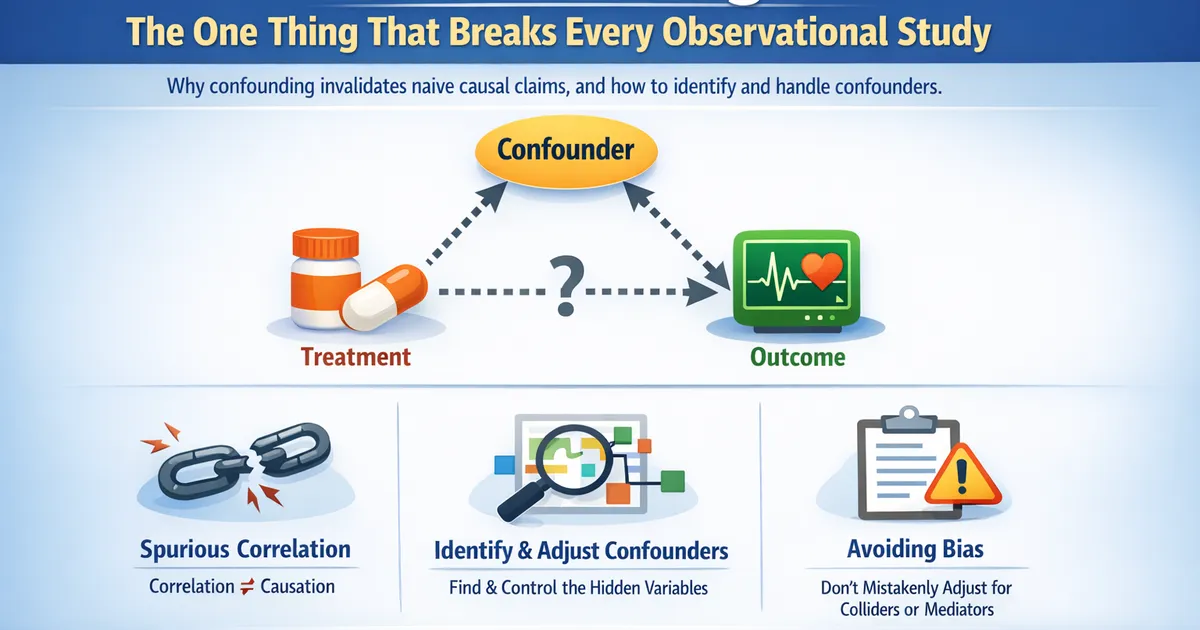
Confounding: The One Thing That Breaks Every Observational Study
What confounding is, why it invalidates naive causal claims, and how to identify and handle confounders in product analytics and observational studies.
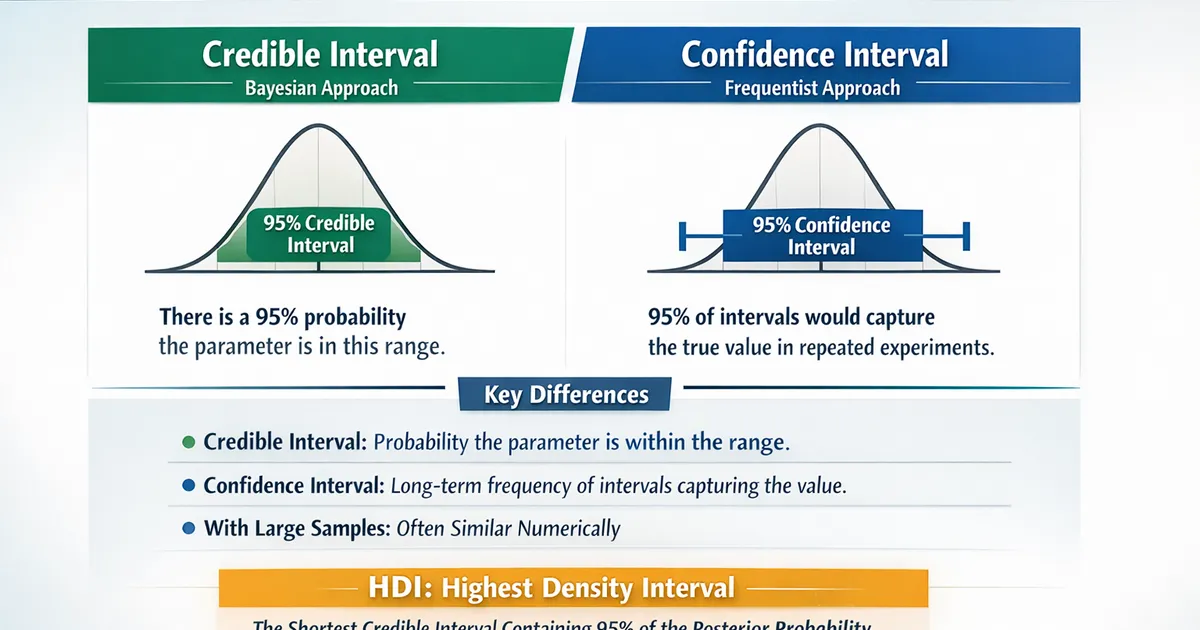
Credible Intervals vs. Confidence Intervals: What Changes
Understand the real difference between credible and confidence intervals. Learn what each actually means, when it matters, and how to interpret both correctly.
