StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.

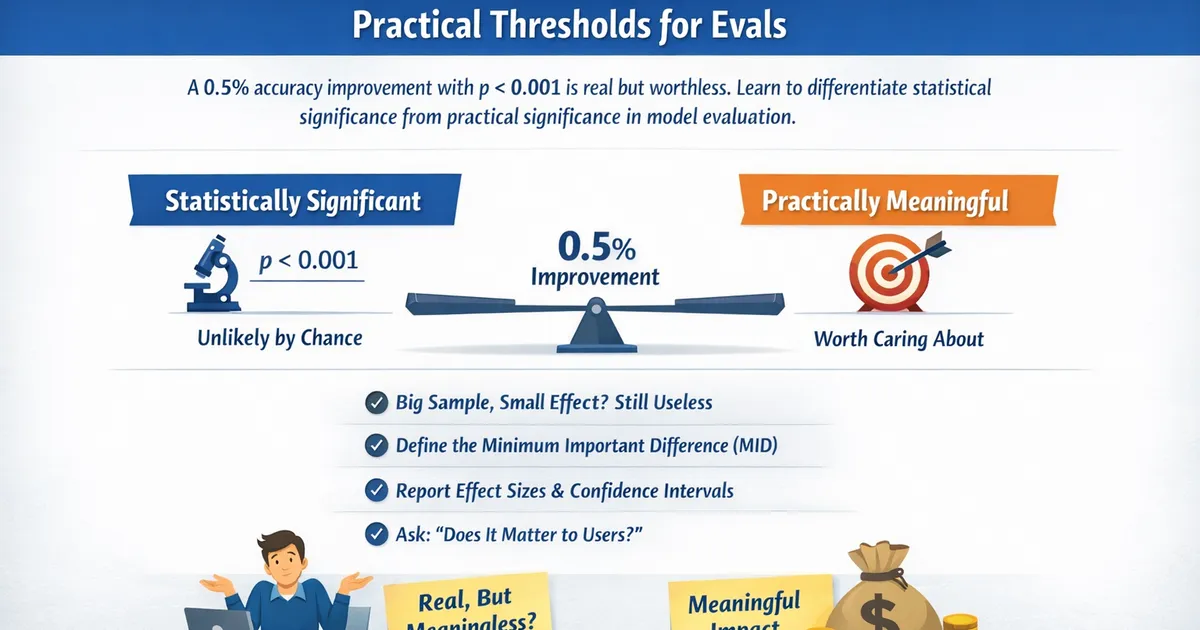
Bootstrap for Metric Deltas: AUC, F1, and Other ML Metrics
How to compute confidence intervals and p-values for differences in ML metrics like AUC, F1, and precision. Learn paired bootstrap for defensible model comparisons.

Calibration Checks: Brier Score and Reliability Diagrams
A model can have high accuracy but terrible probability estimates. Learn how to assess calibration with Brier score, ECE, and reliability diagrams.
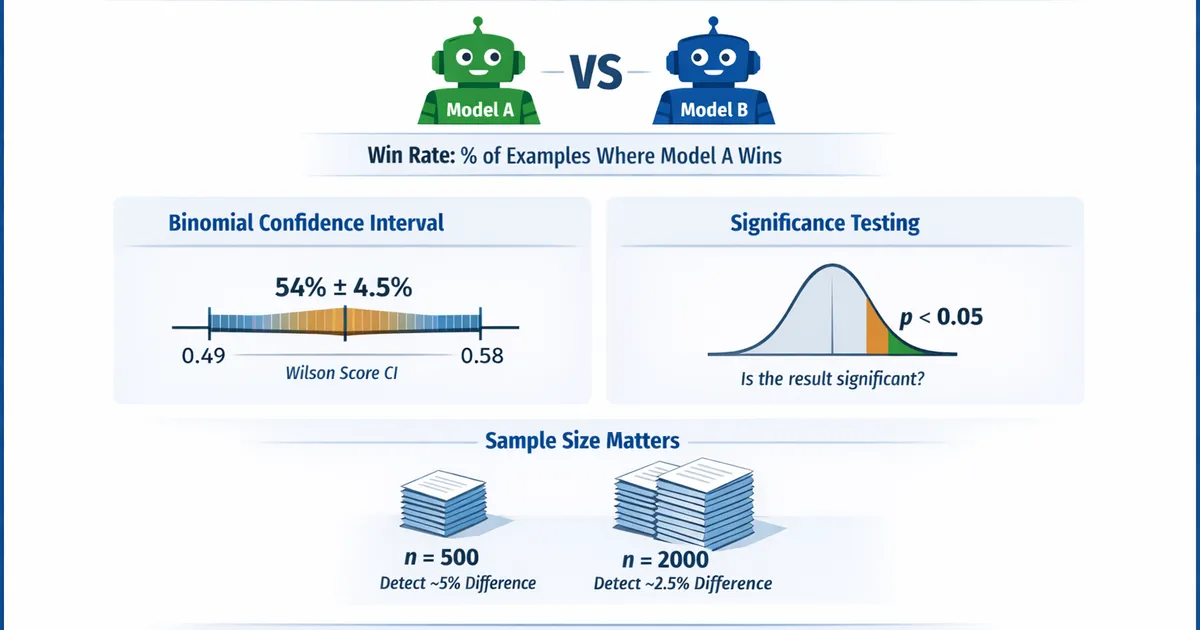
Comparing Two Models: Win Rate, Binomial CI, and Proper Tests
How to rigorously compare two ML models using win rate analysis. Learn about binomial confidence intervals, significance tests, and how many examples you actually need.

Drift Detection: KS Test, PSI, and Interpreting Signals
How to detect when your model's inputs or outputs have shifted. Learn about KS tests, Population Stability Index, and when drift actually matters.
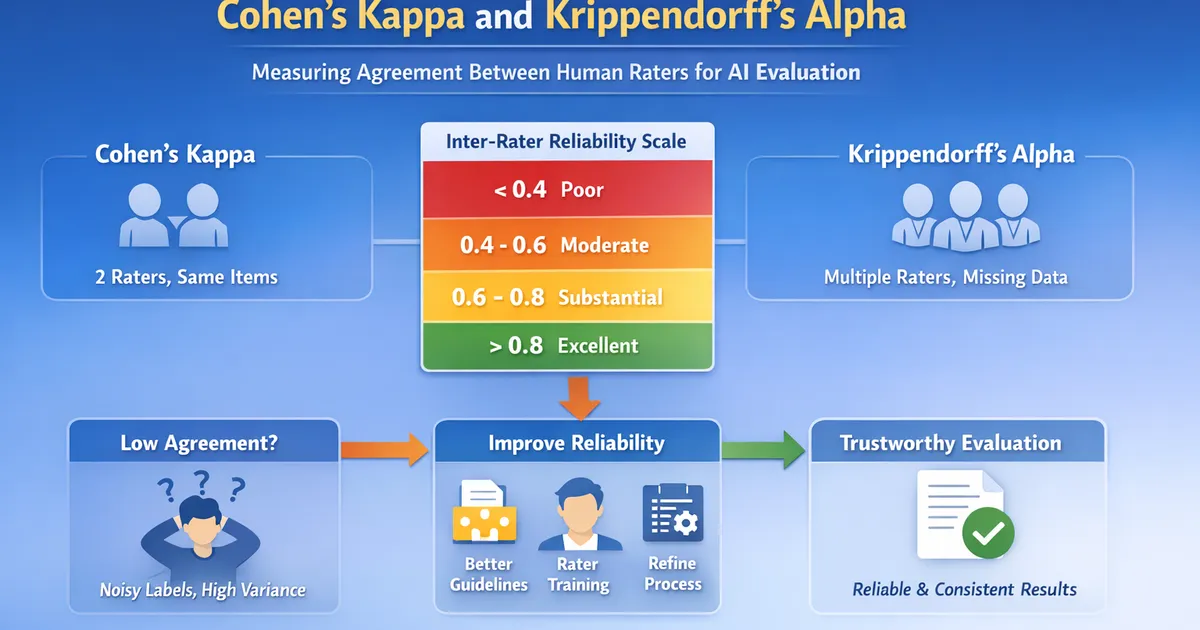
Inter-Rater Reliability: Cohen's Kappa and Krippendorff's Alpha
How to measure agreement between human raters for AI evaluation. Learn when to use Cohen's Kappa vs. Krippendorff's Alpha, how to interpret values, and what to do when agreement is low.

Model Evaluation & Human Ratings Significance for AI Products
Statistical rigor for ML/AI evaluation: comparing model performance, analyzing human ratings, detecting drift, and making defensible decisions. A comprehensive guide for AI practitioners and product teams.

Multiple Prompts and Metrics: Controlling False Discoveries in Evals
When evaluating models across many prompts or metrics, false positives multiply. Learn how to control false discovery rate and make defensible claims about model improvements.

Paired Evaluation: McNemar's Test for Before/After Classification
When the same examples are evaluated by two models, use McNemar's test for proper inference. Learn why paired analysis is more powerful and how to implement it correctly.