StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.
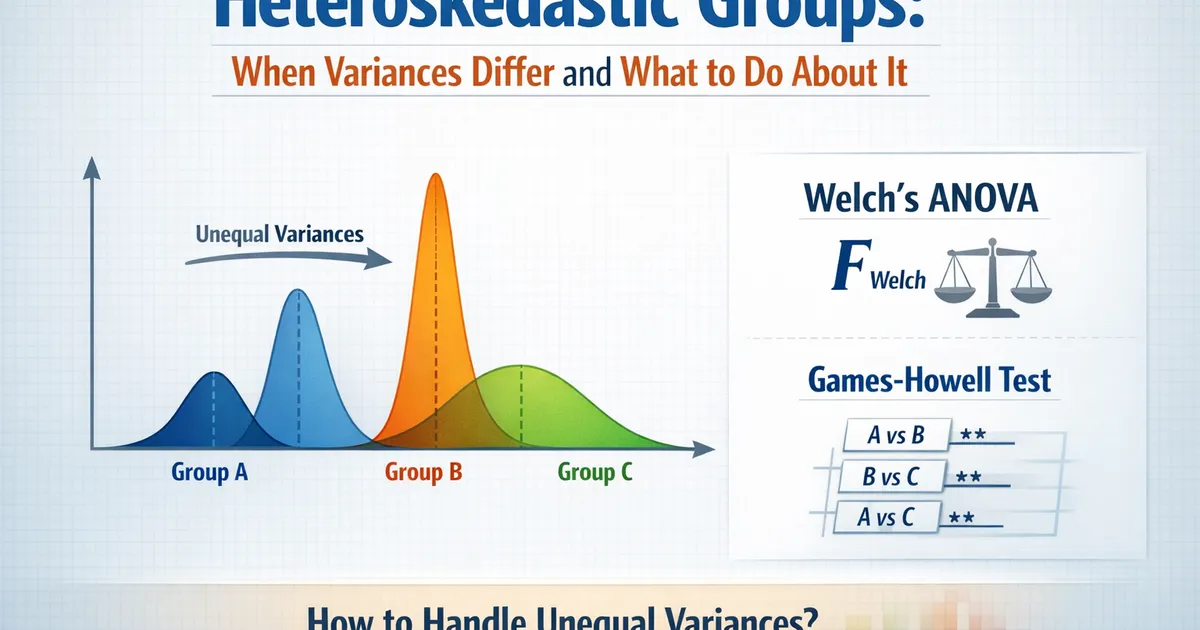
Heteroskedastic Groups: When Variances Differ and What to Do About It
How to handle multi-group comparisons when variances are unequal. Covers Welch's ANOVA, Games-Howell post-hoc, and why this matters more than non-normality.

Independence: The Silent Killer of Statistical Validity
The independence assumption is the most critical and most commonly violated. Learn to detect non-independence from repeated measures, clustering, and time series—and what to do about it.
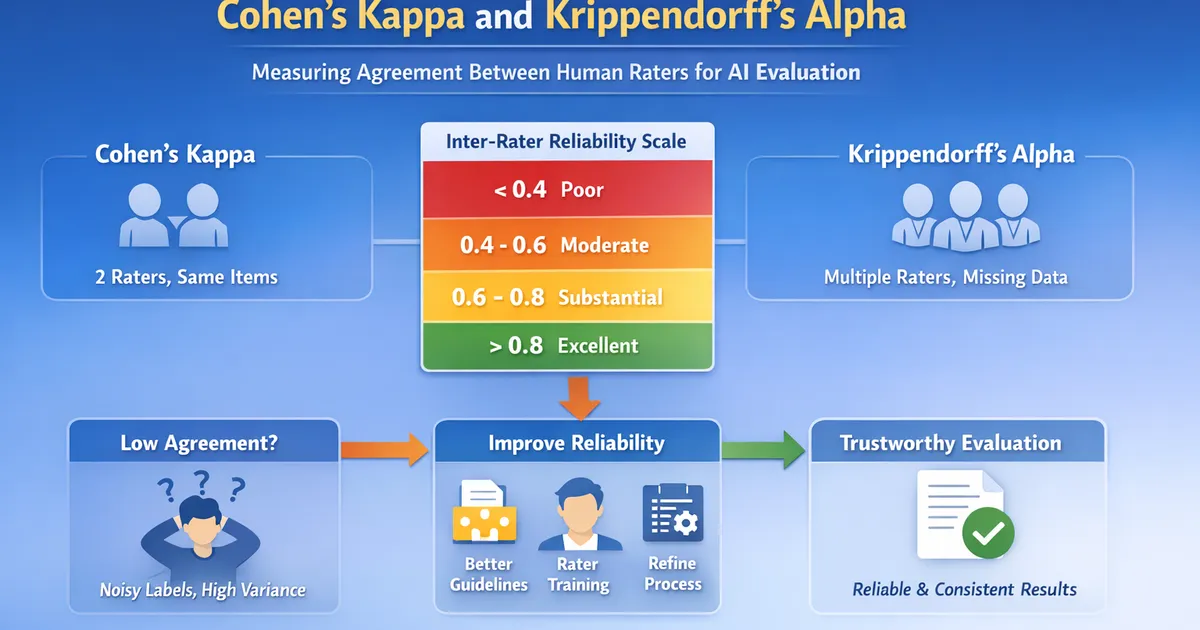
Inter-Rater Reliability: Cohen's Kappa and Krippendorff's Alpha
How to measure agreement between human raters for AI evaluation. Learn when to use Cohen's Kappa vs. Krippendorff's Alpha, how to interpret values, and what to do when agreement is low.
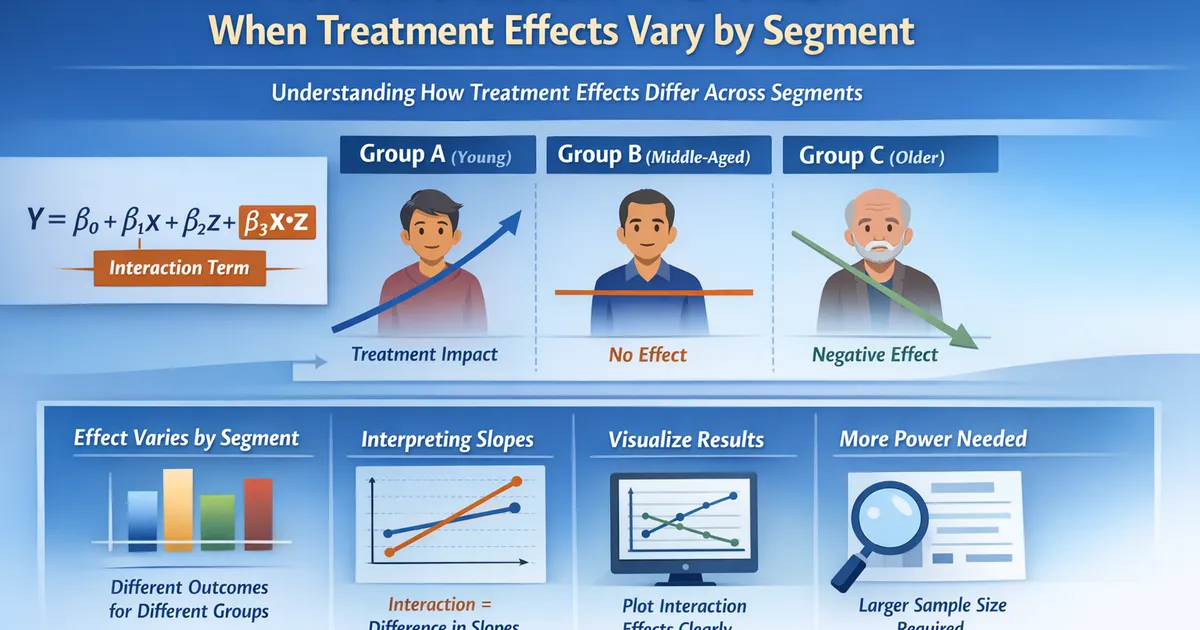
Interaction Terms: When Treatment Effects Vary by Segment
A practical guide to interaction effects in regression. Learn when to include interactions, how to interpret them correctly, and common pitfalls when testing whether treatment effects differ across segments.
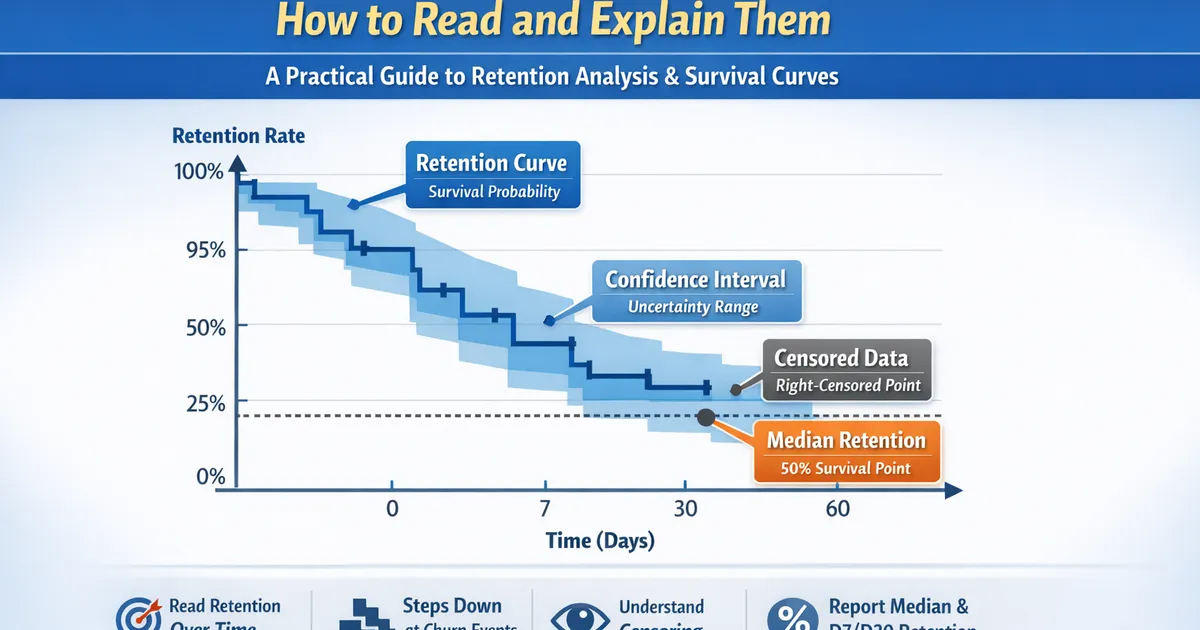
Kaplan-Meier Curves for Retention: How to Read and Explain Them
A practical guide to Kaplan-Meier survival curves for product retention analysis. Learn to create, interpret, and explain retention curves to stakeholders, with handling for censoring and confidence intervals.
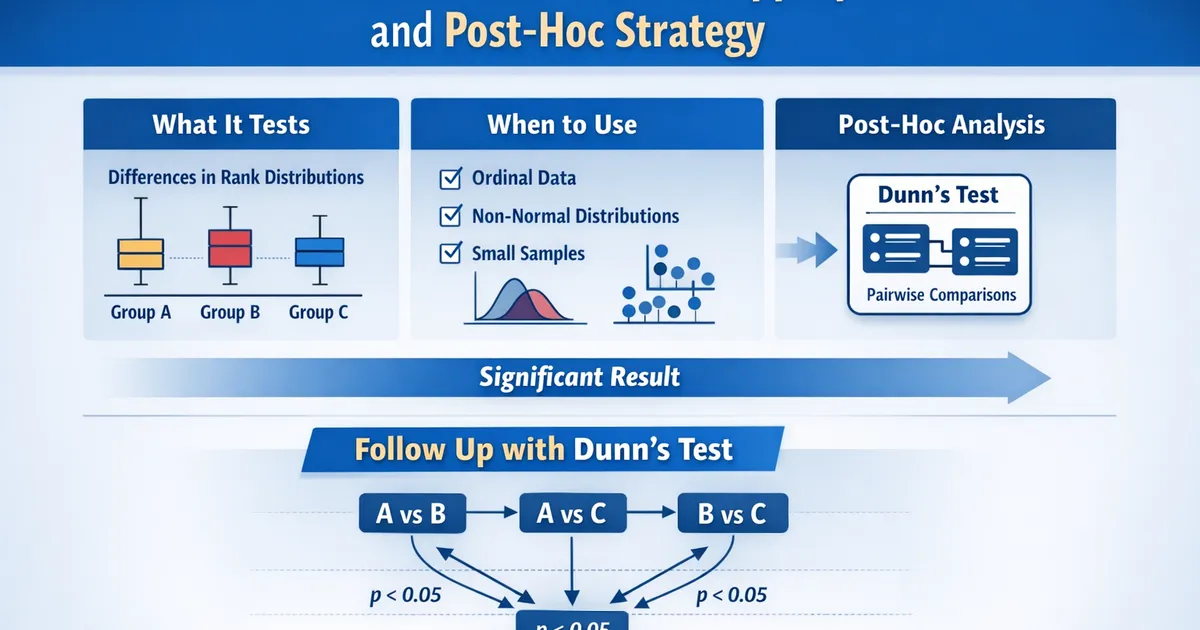
Kruskal-Wallis Test: When It's Appropriate and Post-Hoc Strategy
Understanding the Kruskal-Wallis test for comparing multiple groups without normality assumptions. Covers what it actually tests, when to use it, and how to follow up with Dunn's test.
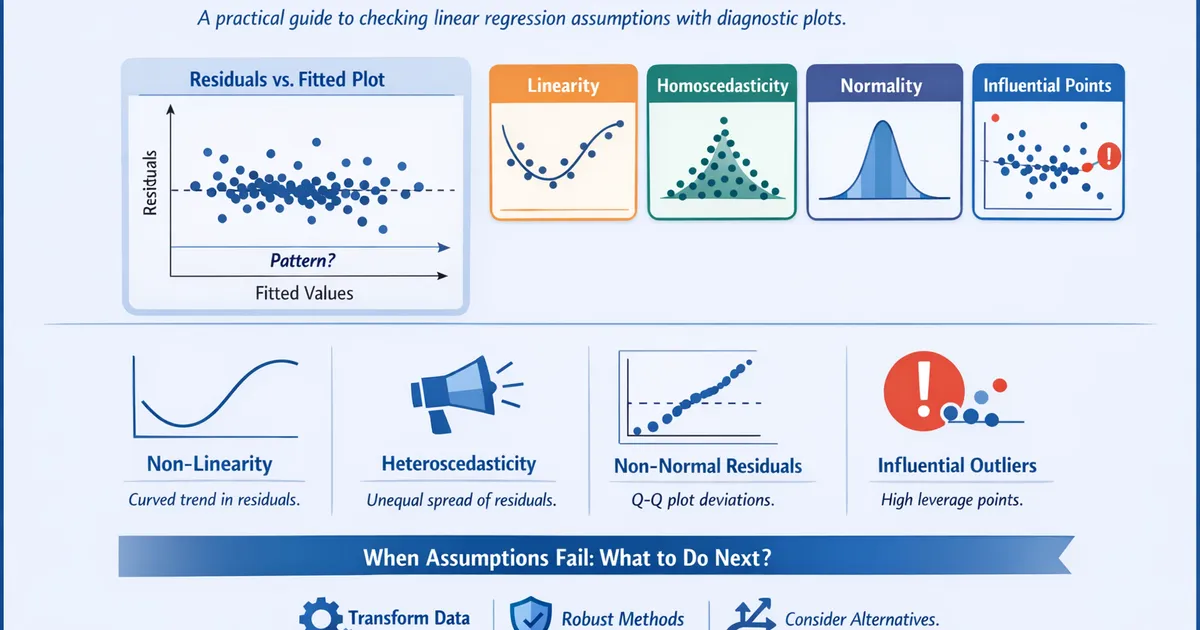
Linear Regression Assumptions and Diagnostics in Practice
A practical guide to checking linear regression assumptions with diagnostic plots. Learn what violations actually look like, when they matter, and what to do when assumptions fail.
Log-Rank Test: When It's Appropriate and Common Misuses
A practical guide to the log-rank test for comparing survival curves. Learn when it works, when it fails, and better alternatives when proportional hazards don't hold.
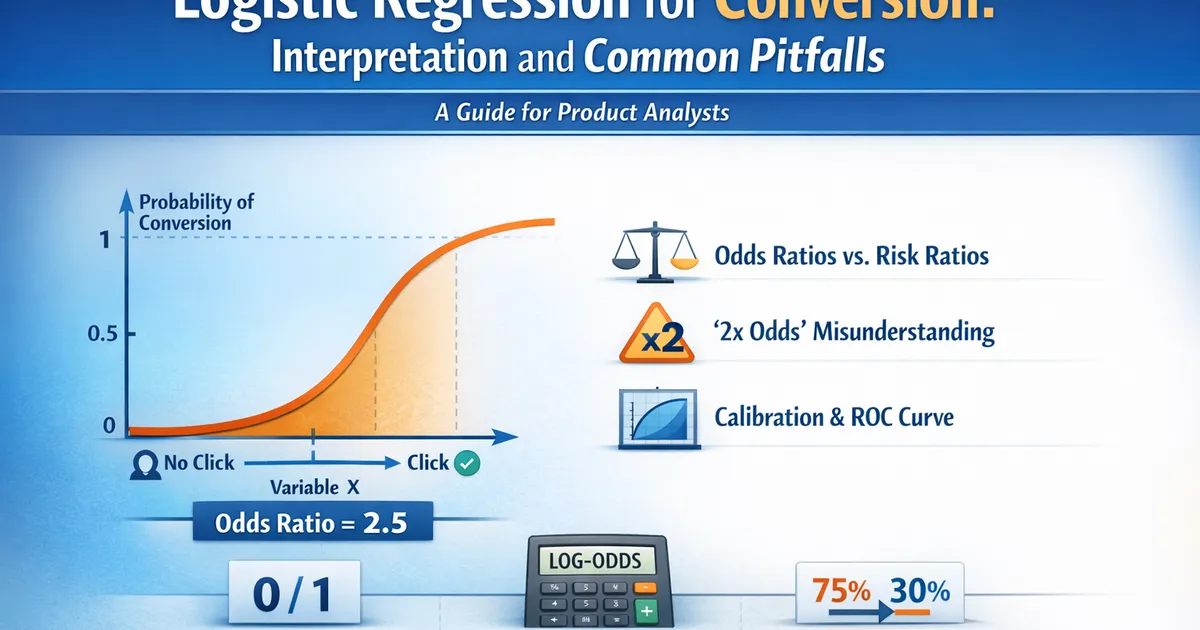
Logistic Regression for Conversion: Interpretation and Common Pitfalls
A practical guide to logistic regression for product analysts. Learn to interpret odds ratios correctly, avoid common mistakes, and communicate results to stakeholders who don't think in log-odds.

Mann-Whitney U Test: What It Actually Tests and Common Misinterpretations
The Mann-Whitney U test is widely misunderstood. Learn what it actually tests (stochastic dominance), when it's appropriate, and why it's not always a substitute for the t-test.
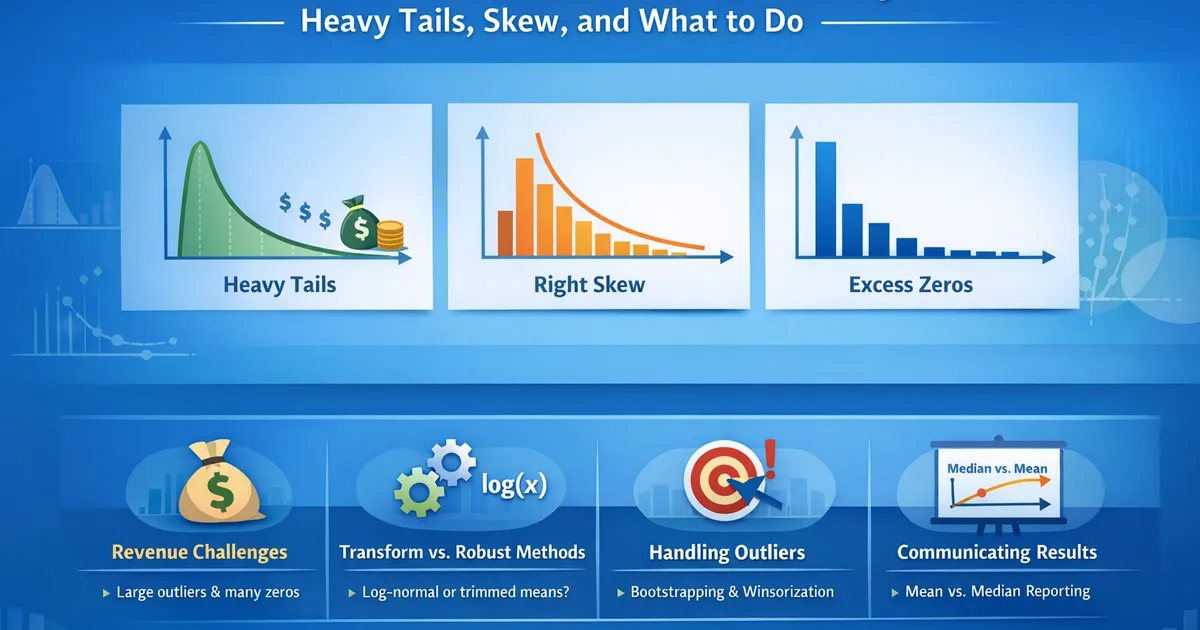
Metric Distributions in Product Analytics: Heavy Tails, Skew, and What to Do
A comprehensive guide to handling real-world metric distributions in product analytics. Learn why revenue is hard, how to deal with zeros, when to transform vs. use robust methods, and how to communicate results on skewed data.
