Contents
Kruskal-Wallis Test: When It's Appropriate and Post-Hoc Strategy
Understanding the Kruskal-Wallis test for comparing multiple groups without normality assumptions. Covers what it actually tests, when to use it, and how to follow up with Dunn's test.
Quick Hits
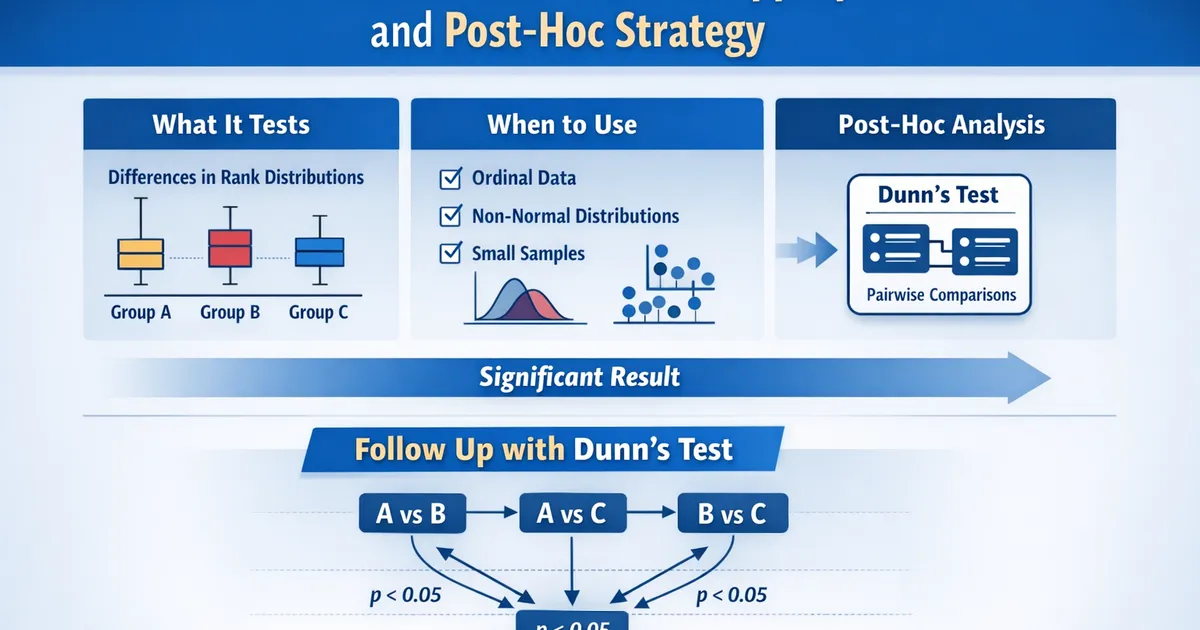
- •Kruskal-Wallis is the non-parametric extension of Mann-Whitney to 3+ groups
- •It tests whether groups differ in distribution, not whether means differ
- •Follow significant results with Dunn's test for pairwise comparisons
- •Use it for ordinal data, severely non-normal distributions, or as a robustness check
TL;DR
Kruskal-Wallis is the non-parametric alternative to one-way ANOVA, extending Mann-Whitney to three or more groups. It tests whether groups differ in their rank distributions—not whether means or medians differ specifically. Use it for ordinal data, severely non-normal distributions, or as a robustness check. Follow significant results with Dunn's test for pairwise comparisons.
What Kruskal-Wallis Actually Tests
The Procedure
- Rank all observations from all groups together (1 = smallest)
- Calculate mean rank for each group
- Test whether mean ranks differ more than expected by chance
The Hypothesis
- H₀: All groups have the same distribution
- H₁: At least one group has a different distribution
This is NOT the same as testing whether means differ. Groups can have identical means but different Kruskal-Wallis results (different shapes), or different means but non-significant Kruskal-Wallis (symmetric differences that cancel in ranks).
When to Use Kruskal-Wallis
Good Uses
Ordinal data: Rankings, Likert scales, ordered categories where arithmetic means don't make sense.
# Example: customer satisfaction ratings (1-5)
import numpy as np
from scipy import stats
group_a = np.array([4, 5, 3, 4, 5, 4, 5, 5, 4, 4]) # Generally satisfied
group_b = np.array([3, 2, 3, 4, 2, 3, 3, 2, 3, 3]) # Mixed
group_c = np.array([2, 1, 2, 2, 3, 1, 2, 2, 1, 2]) # Generally unsatisfied
stat, p_value = stats.kruskal(group_a, group_b, group_c)
print(f"H-statistic: {stat:.2f}, p-value: {p_value:.4f}")
Severely non-normal data: When distributions are extremely skewed or heavy-tailed and samples are small.
Robustness check: Running alongside ANOVA to verify results aren't driven by distributional assumptions.
When ANOVA Is Better
Comparing means: If your question is specifically about mean differences, ANOVA (or Welch's) is more appropriate and powerful.
Large samples: ANOVA is robust to non-normality with large samples. Kruskal-Wallis doesn't add much.
Business metrics where totals matter: Revenue, conversion counts—means are usually the relevant summary.
Python Implementation
from scipy import stats
import numpy as np
import pandas as pd
def kruskal_wallis_analysis(groups, group_names=None):
"""
Complete Kruskal-Wallis analysis.
"""
if group_names is None:
group_names = [f'Group {i+1}' for i in range(len(groups))]
# Test
h_stat, p_value = stats.kruskal(*groups)
# Effect size: epsilon-squared
n_total = sum(len(g) for g in groups)
k = len(groups)
epsilon_sq = (h_stat - k + 1) / (n_total - k)
# Group statistics
all_data = np.concatenate(groups)
ranks = stats.rankdata(all_data)
start = 0
group_stats = []
for i, (g, name) in enumerate(zip(groups, group_names)):
end = start + len(g)
group_ranks = ranks[start:end]
group_stats.append({
'Group': name,
'n': len(g),
'Mean Rank': np.mean(group_ranks),
'Median': np.median(g),
'IQR': np.percentile(g, 75) - np.percentile(g, 25)
})
start = end
return {
'h_statistic': h_stat,
'p_value': p_value,
'epsilon_squared': epsilon_sq,
'group_stats': pd.DataFrame(group_stats)
}
# Example
np.random.seed(42)
group1 = np.random.exponential(10, 30)
group2 = np.random.exponential(15, 30)
group3 = np.random.exponential(12, 30)
result = kruskal_wallis_analysis([group1, group2, group3], ['A', 'B', 'C'])
print(f"H = {result['h_statistic']:.2f}, p = {result['p_value']:.4f}")
print(f"Effect size (ε²) = {result['epsilon_squared']:.3f}")
print("\nGroup Statistics:")
print(result['group_stats'].to_string(index=False))
R Implementation
# Kruskal-Wallis test
kruskal.test(value ~ group, data = df)
# Effect size
library(rstatix)
kruskal_effsize(df, value ~ group)
Effect Size: Epsilon-Squared
Kruskal-Wallis has its own effect size measure:
Where H is the Kruskal-Wallis statistic, k is number of groups, n is total sample size.
| Interpretation | |
|---|---|
| 0.01 | Small |
| 0.06 | Medium |
| 0.14 | Large |
Post-Hoc: Dunn's Test
After significant Kruskal-Wallis, Dunn's test identifies which groups differ.
import scikit_posthocs as sp
def dunns_test(groups, group_names=None, p_adjust='bonferroni'):
"""
Dunn's test for pairwise comparisons after Kruskal-Wallis.
"""
if group_names is None:
group_names = [f'Group {i+1}' for i in range(len(groups))]
# Create dataframe
all_data = np.concatenate(groups)
labels = np.repeat(group_names, [len(g) for g in groups])
df = pd.DataFrame({'value': all_data, 'group': labels})
# Dunn's test
result = sp.posthoc_dunn(df, val_col='value', group_col='group',
p_adjust=p_adjust)
return result
# Follow up significant Kruskal-Wallis
if result['p_value'] < 0.05:
dunn_result = dunns_test([group1, group2, group3], ['A', 'B', 'C'])
print("\nDunn's Test (Bonferroni-adjusted p-values):")
print(dunn_result)
R Implementation
library(FSA)
dunnTest(value ~ group, data = df, method = "bonferroni")
# Or using PMCMRplus
library(PMCMRplus)
kwAllPairsDunnTest(value ~ group, data = df, p.adjust.method = "bonferroni")
Correction Methods
| Method | Description | When to Use |
|---|---|---|
| Bonferroni | Conservative, controls FWER | Few comparisons, need strong control |
| Holm | Less conservative than Bonferroni | Default good choice |
| Benjamini-Hochberg | Controls FDR | Many comparisons, some false positives acceptable |
Comparing ANOVA and Kruskal-Wallis
def compare_anova_kw(groups, group_names=None):
"""
Run both ANOVA and Kruskal-Wallis for comparison.
"""
# ANOVA
f_stat, anova_p = stats.f_oneway(*groups)
# Kruskal-Wallis
h_stat, kw_p = stats.kruskal(*groups)
print("Comparison of ANOVA and Kruskal-Wallis:")
print(f" ANOVA: F = {f_stat:.2f}, p = {anova_p:.4f}")
print(f" Kruskal-Wallis: H = {h_stat:.2f}, p = {kw_p:.4f}")
if (anova_p < 0.05) == (kw_p < 0.05):
print(" Both tests agree on significance.")
else:
print(" Tests disagree! Investigate distribution shapes.")
return {
'anova': {'f': f_stat, 'p': anova_p},
'kruskal_wallis': {'h': h_stat, 'p': kw_p}
}
compare_anova_kw([group1, group2, group3])
When Results Differ
If ANOVA and Kruskal-Wallis give different conclusions:
- Check distribution shapes—are they similar across groups?
- If shapes differ, Kruskal-Wallis detects this; ANOVA doesn't
- If you care about means specifically, trust ANOVA (or use Welch's)
- If you care about "tends to be larger," trust Kruskal-Wallis
Common Mistakes
Calling It a "Median Test"
Kruskal-Wallis doesn't test medians specifically. Groups with equal medians can have significant Kruskal-Wallis results if their distributions differ.
Using It When ANOVA Would Be Better
For comparing means with moderately non-normal data and reasonable samples, ANOVA is often more powerful and directly tests your question.
Ignoring Effect Size
A significant H-statistic doesn't tell you the magnitude. Always report epsilon-squared or similar effect size.
Wrong Post-Hoc Test
Don't use Tukey's HSD after Kruskal-Wallis—use Dunn's test or other rank-based post-hoc procedures.
Practical Workflow
def kruskal_workflow(groups, group_names, alpha=0.05):
"""
Complete Kruskal-Wallis workflow.
"""
# 1. Descriptive statistics
print("Step 1: Descriptive Statistics")
for name, g in zip(group_names, groups):
print(f" {name}: n={len(g)}, median={np.median(g):.2f}, "
f"IQR=[{np.percentile(g, 25):.2f}, {np.percentile(g, 75):.2f}]")
# 2. Kruskal-Wallis test
h_stat, p_value = stats.kruskal(*groups)
n_total = sum(len(g) for g in groups)
k = len(groups)
epsilon_sq = (h_stat - k + 1) / (n_total - k)
print(f"\nStep 2: Kruskal-Wallis Test")
print(f" H({k-1}) = {h_stat:.2f}, p = {p_value:.4f}")
print(f" Effect size ε² = {epsilon_sq:.3f}")
# 3. Post-hoc if significant
if p_value < alpha:
print(f"\nStep 3: Post-Hoc Comparisons (Dunn's test)")
all_data = np.concatenate(groups)
labels = np.repeat(group_names, [len(g) for g in groups])
df = pd.DataFrame({'value': all_data, 'group': labels})
dunn = sp.posthoc_dunn(df, val_col='value', group_col='group',
p_adjust='holm')
print(dunn)
else:
print(f"\nStep 3: No post-hoc needed (p = {p_value:.4f} > {alpha})")
kruskal_workflow([group1, group2, group3], ['A', 'B', 'C'])
Related Methods
- Comparing More Than Two Groups — The pillar guide
- Mann-Whitney U Test: What It Actually Tests — Two-group equivalent
- Post-Hoc Tests: Decision Tree — Choosing the right follow-up
Key Takeaway
Kruskal-Wallis tests whether groups differ in their rank distributions—not whether means or medians differ. Use it for ordinal data or when ANOVA assumptions are severely violated. Follow significant results with Dunn's test for pairwise comparisons. When comparing means is your goal, ANOVA (possibly Welch's) is usually more appropriate.
References
- https://www.jstor.org/stable/2280779
- https://www.jstor.org/stable/2529444
- Kruskal, W. H., & Wallis, W. A. (1952). Use of ranks in one-criterion variance analysis. *Journal of the American Statistical Association*, 47(260), 583-621.
- Dunn, O. J. (1964). Multiple comparisons using rank sums. *Technometrics*, 6(3), 241-252.
- Tomczak, M., & Tomczak, E. (2014). The need to report effect size estimates revisited. *Trends in Sport Sciences*, 21(1), 19-25.
Frequently Asked Questions
Does Kruskal-Wallis test medians?
When should I use Kruskal-Wallis instead of ANOVA?
What post-hoc test follows Kruskal-Wallis?
Key Takeaway
Kruskal-Wallis tests whether groups differ in their rank distributions—not whether means or medians differ. Use it for ordinal data or when ANOVA assumptions are severely violated. Follow significant results with Dunn's test for pairwise comparisons.