StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.
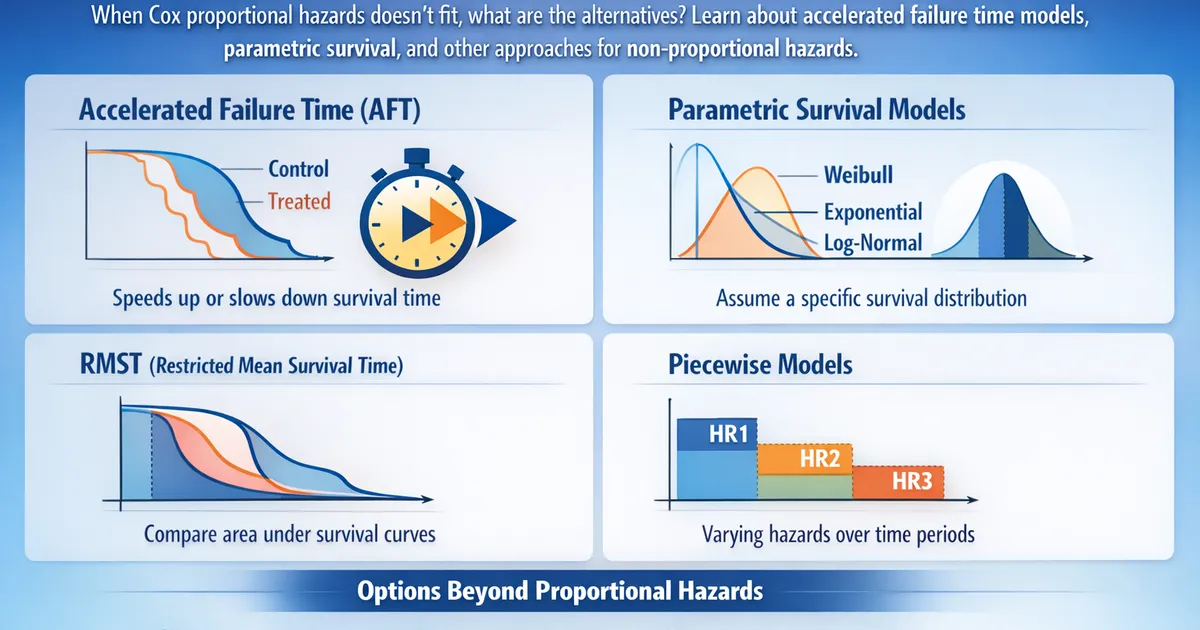
Alternatives to Cox: Accelerated Failure Time and Other Models
When Cox proportional hazards doesn't fit, what are the alternatives? Learn about accelerated failure time models, parametric survival, and other approaches for non-proportional hazards.

Analytics Reporting That Doesn't Get You Killed in Review
How to communicate statistical results to stakeholders without getting destroyed in review. Templates, common mistakes, and strategies for building trust through transparency.
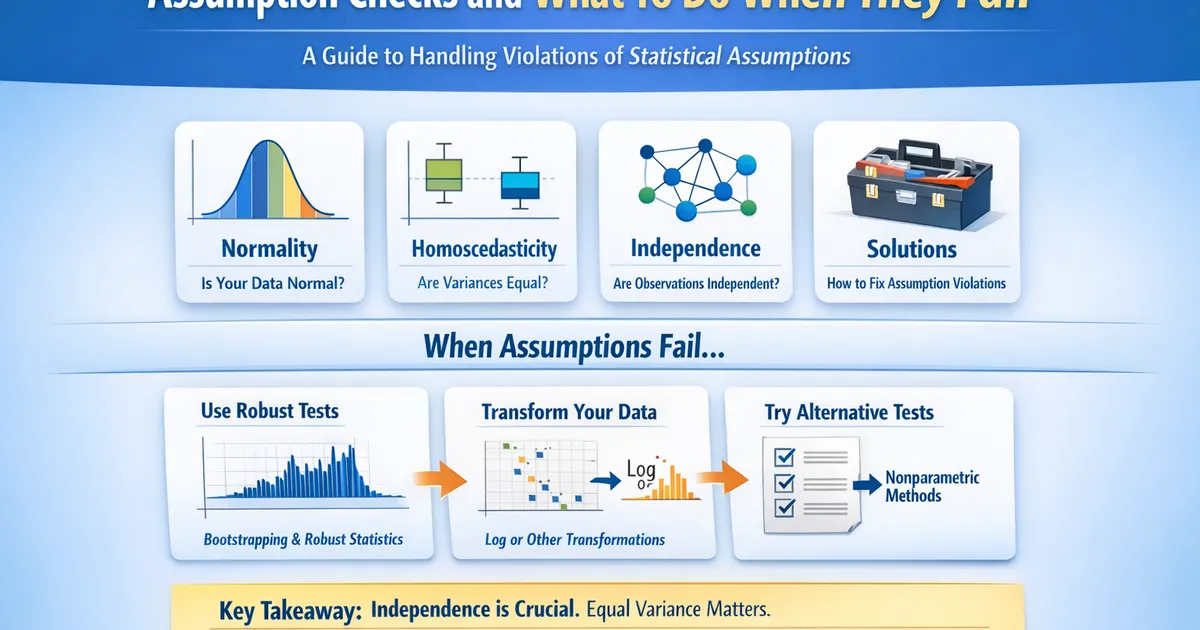
Assumption Checks and What To Do When They Fail
A comprehensive guide to statistical assumptions in hypothesis testing. Learn which assumptions matter most, how to diagnose violations, and what to do when your data doesn't fit the textbook requirements.

Audit Trails: How to Document Assumptions, Data Filters, and Analysis Decisions
Build analysis audit trails that let anyone understand and reproduce your work. Document data filters, exclusions, assumptions, and decision points so future investigations are possible.
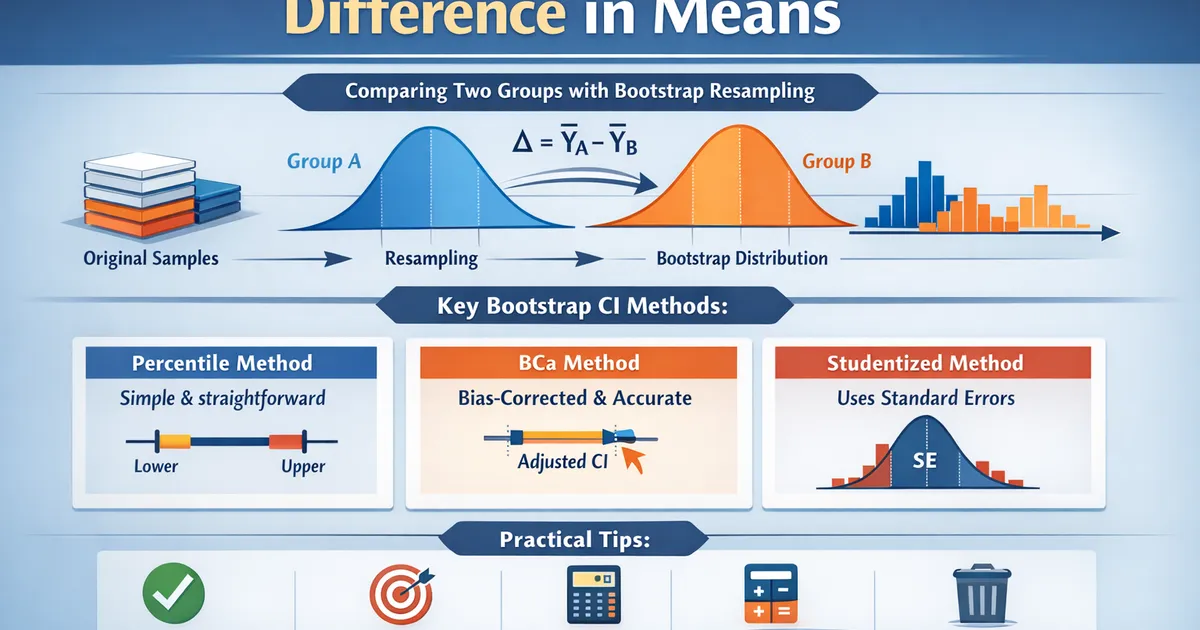
Bootstrap Confidence Intervals for Difference in Means
How to use bootstrap resampling to construct confidence intervals for comparing two groups. Covers percentile, BCa, and studentized methods with practical guidance.

Bootstrap for Heavy-Tailed Metrics: Best Practices and Gotchas
How to use bootstrap correctly for revenue, engagement, and other heavy-tailed metrics. Learn about BCa intervals, when bootstrap fails, and how many resamples you actually need.

Bootstrap for Metric Deltas: AUC, F1, and Other ML Metrics
How to compute confidence intervals and p-values for differences in ML metrics like AUC, F1, and precision. Learn paired bootstrap for defensible model comparisons.

Calibration Checks: Brier Score and Reliability Diagrams
A model can have high accuracy but terrible probability estimates. Learn how to assess calibration with Brier score, ECE, and reliability diagrams.
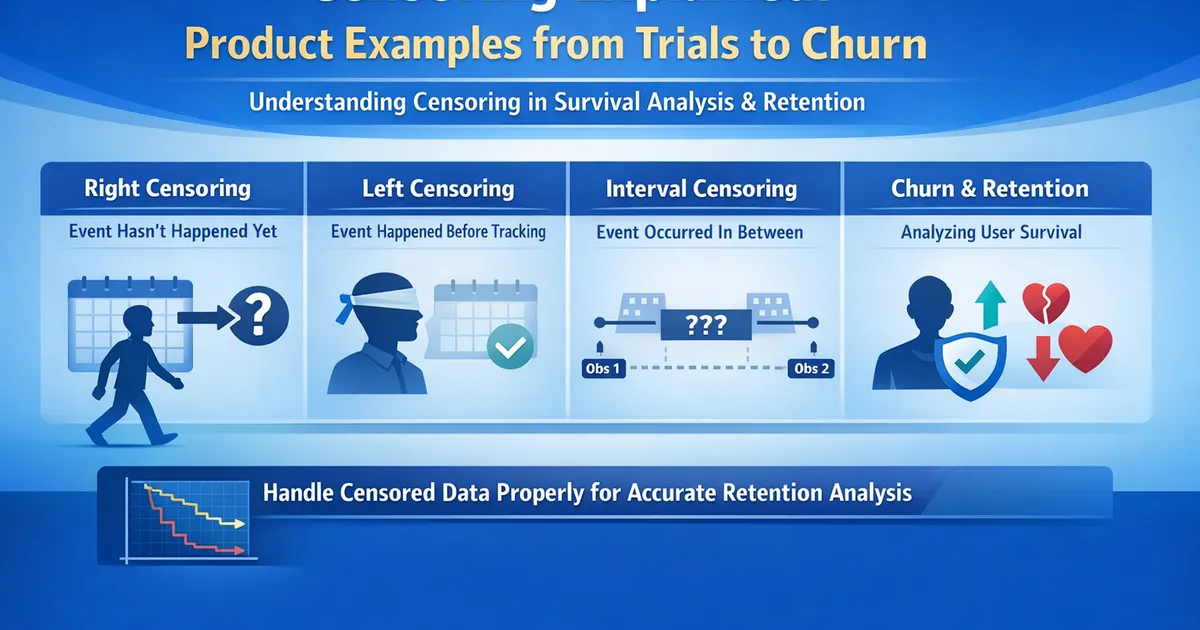
Censoring Explained: Product Examples from Trials to Churn
A practical guide to understanding censoring in survival analysis. Learn the different types of censoring, why it matters for retention analysis, and how to identify and handle censoring in your product data.
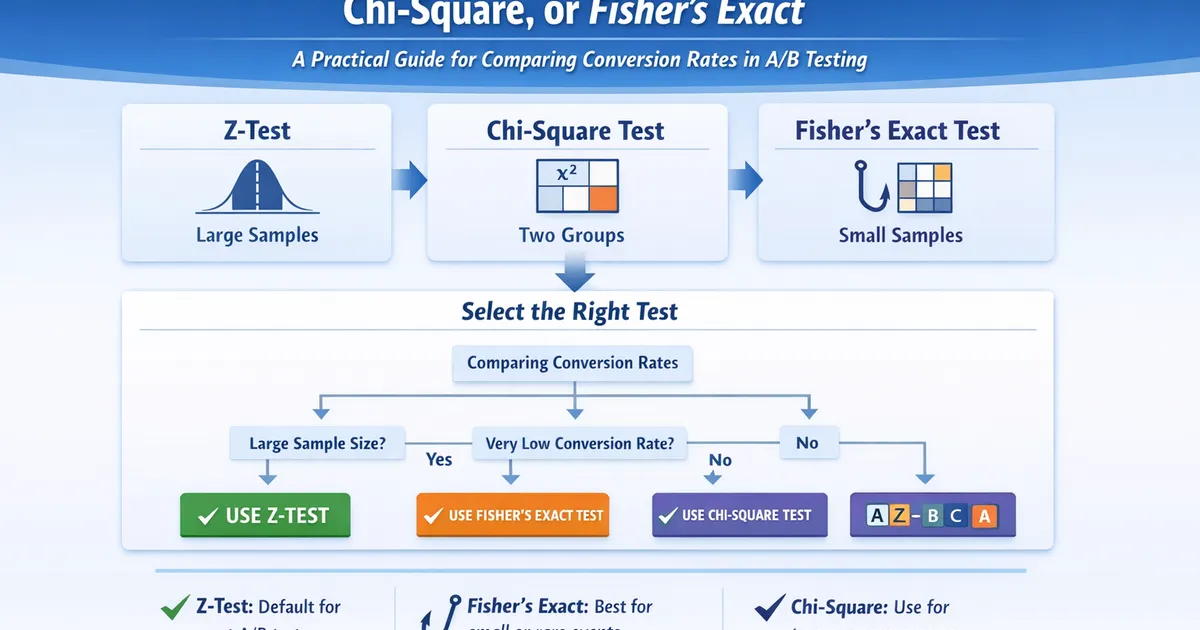
Choosing the Right Test for Conversion Rates: Z-Test, Chi-Square, or Fisher's Exact
A practical decision framework for selecting between z-test, chi-square test, and Fisher's exact test when comparing conversion rates in A/B experiments.

Clustered Experiments: Geo Tests, Classrooms, and Independence Violations
How to handle A/B tests where observations aren't independent—geo experiments, marketplace tests, social features, and other settings where users are clustered or connected.