StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.
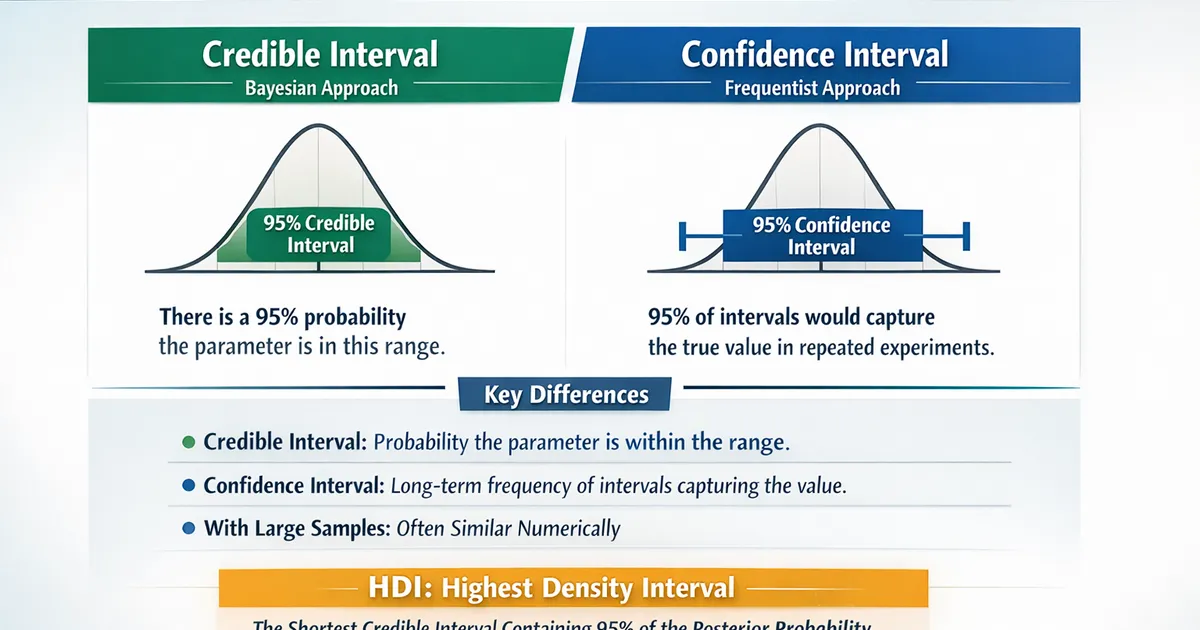
Credible Intervals vs. Confidence Intervals: What Changes
Understand the real difference between credible and confidence intervals. Learn what each actually means, when it matters, and how to interpret both correctly.

DAGs for Analysts: Drawing Your Assumptions Before You Analyze
How directed acyclic graphs help analysts identify confounders, avoid collider bias, and choose the right variables to control for in causal analysis.
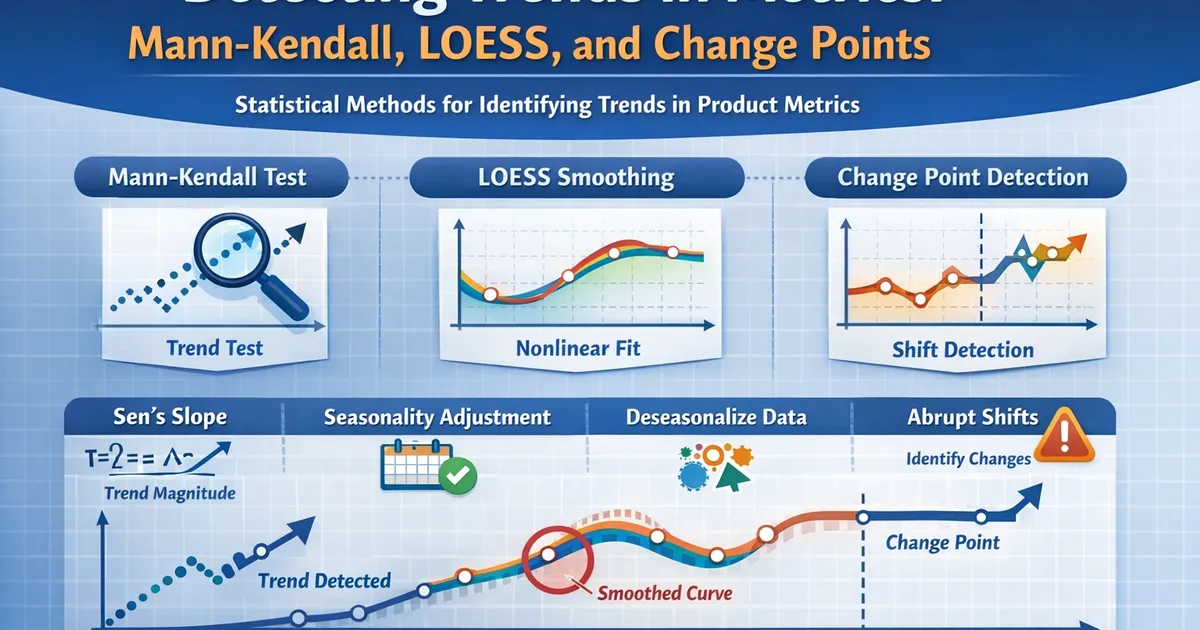
Detecting Trends in Metrics: Mann-Kendall, LOESS, and Change Points
How to statistically detect trends in product metrics using Mann-Kendall tests, LOESS smoothing, and change point analysis.
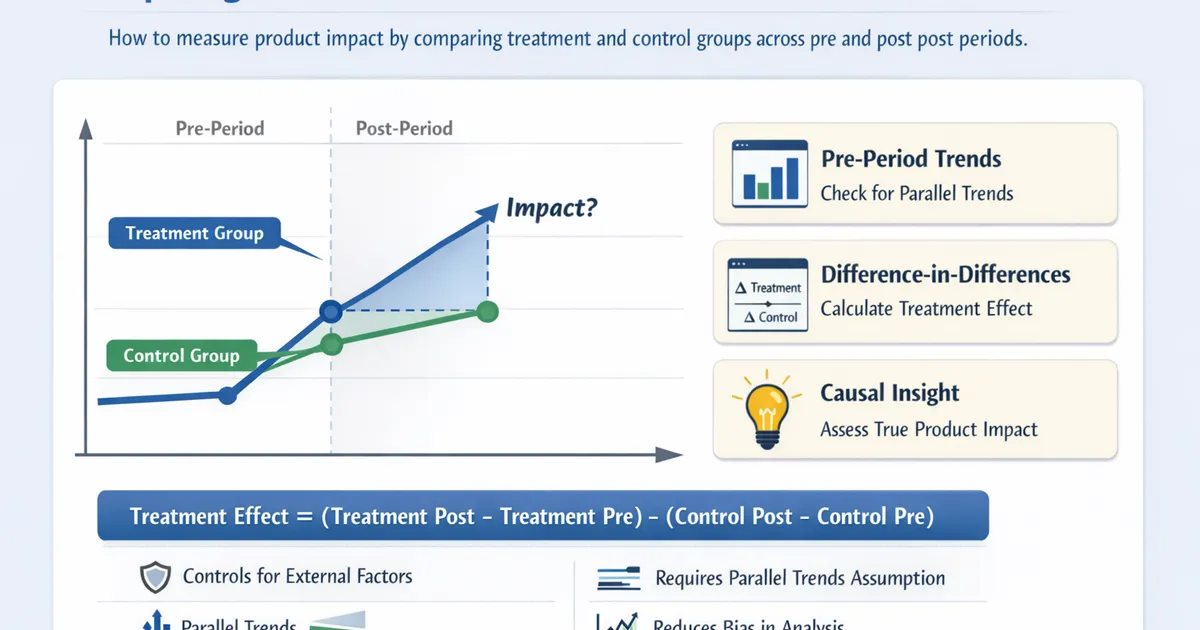
Comparing Pre/Post Periods: Difference-in-Differences for Product
How to use difference-in-differences to measure product impact by comparing treatment and control groups across pre and post periods.
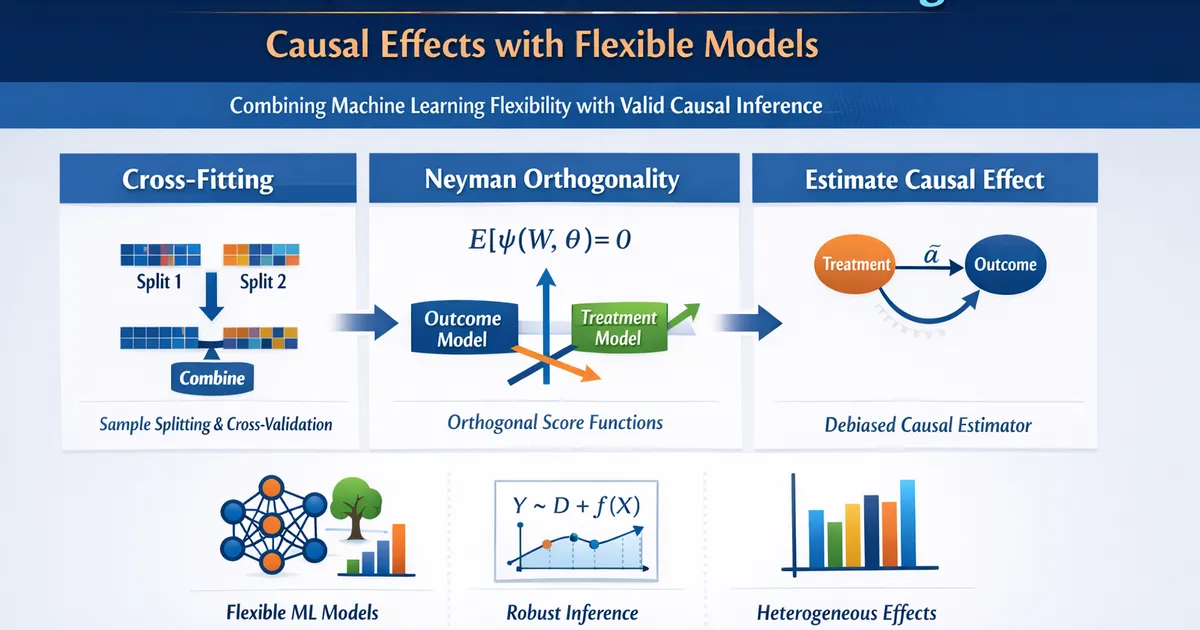
Double/Debiased Machine Learning: Causal Effects with Flexible Models
How double/debiased machine learning combines ML flexibility with valid causal inference. Learn cross-fitting, Neyman orthogonality, and practical DML workflows.

Forecasting Product Metrics: ARIMA, Prophet, and When Simple Wins
A practical guide to forecasting product metrics with ARIMA, Prophet, and baseline methods. Learn when complexity helps and when it hurts.

Granger Causality: Does Feature Usage Actually Drive Retention?
How to use Granger causality to test whether feature usage predicts retention, and why correlation over time is not causation.
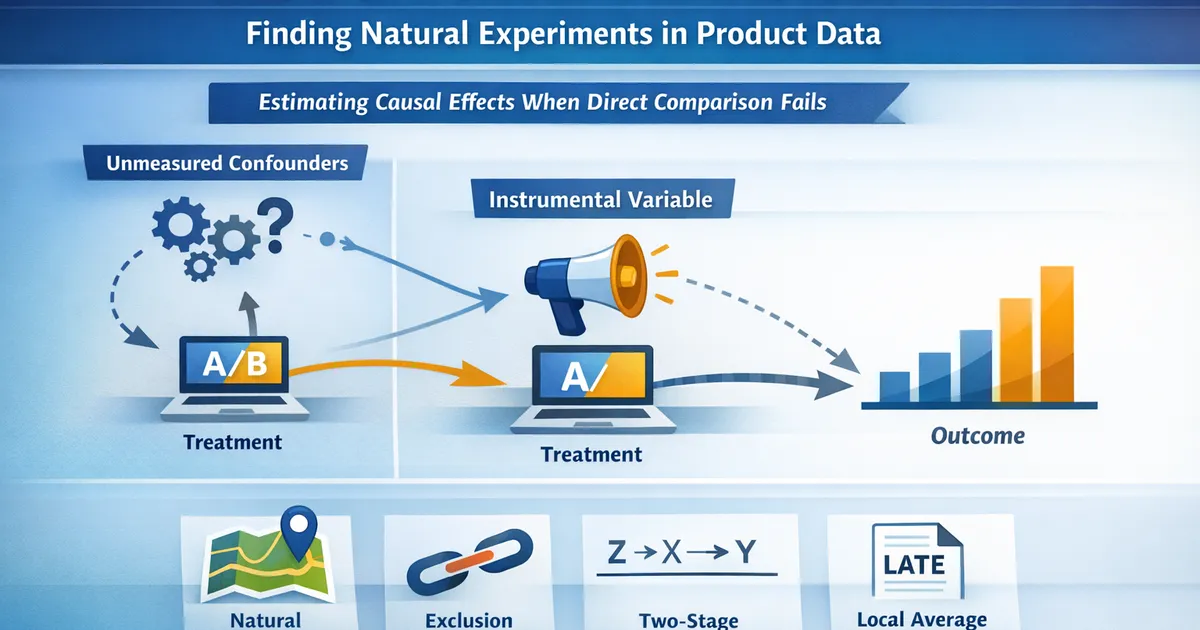
Instrumental Variables: Finding Natural Experiments in Product Data
How instrumental variables let you estimate causal effects when unmeasured confounding makes direct comparison impossible. Practical IV examples for tech.

Interrupted Time Series: Measuring Impact Without a Control Group
How to use interrupted time series analysis to measure causal impact of launches, policy changes, and events without a control group.
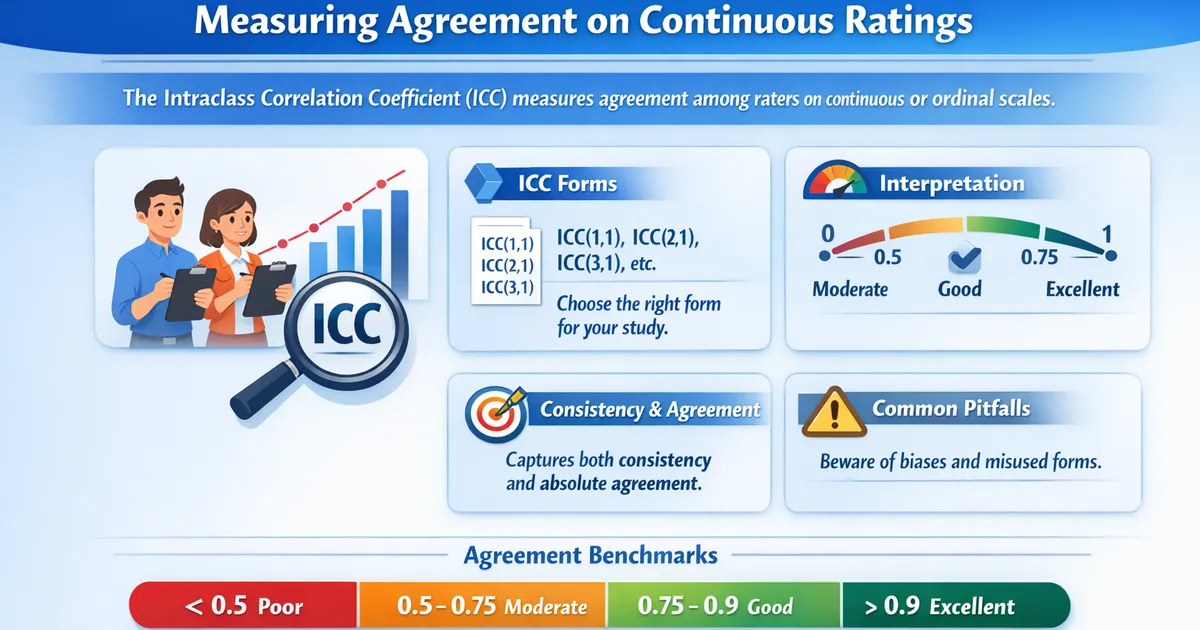
Intraclass Correlation: Measuring Agreement on Continuous Ratings
Intraclass Correlation Coefficient (ICC) measures agreement among raters on continuous or ordinal scales. Learn which ICC form to use, how to interpret values, and common pitfalls.

Kolmogorov-Smirnov Test: Comparing Distributions and Detecting Drift
A practical guide to the KS test for comparing distributions and detecting drift. Learn the one-sample and two-sample variants, common pitfalls, and when to use alternatives.
