StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.
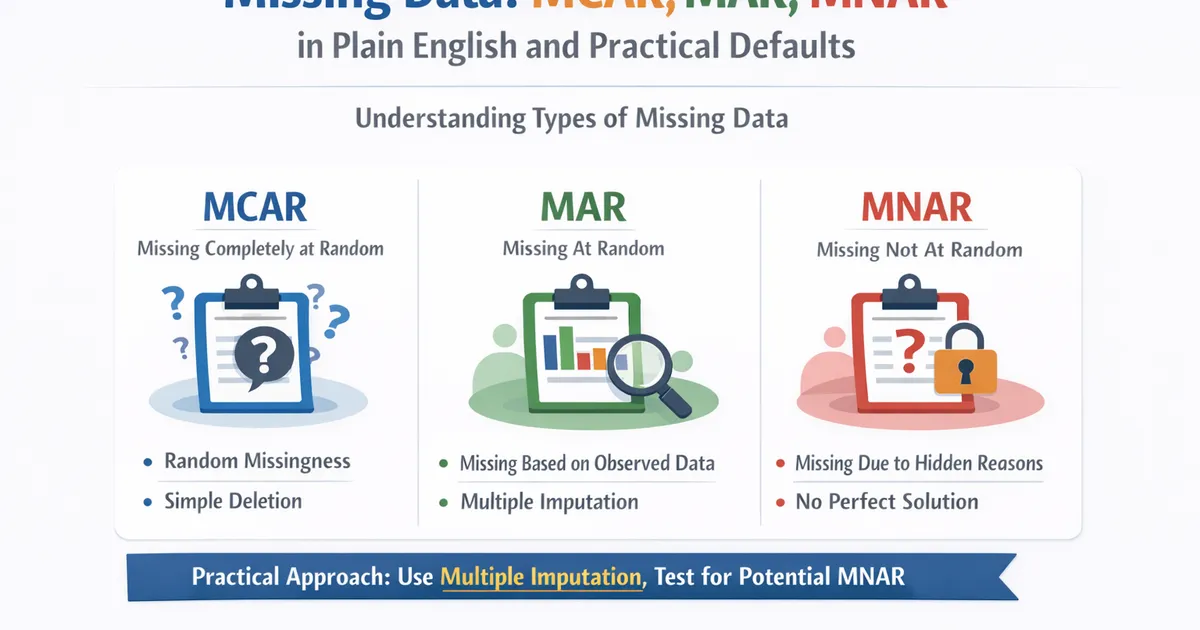
Missing Data: MCAR, MAR, MNAR in Plain English and Practical Defaults
A practical guide to handling missing data. Learn the three types of missingness, why it matters for your analysis, and sensible default approaches for product analytics.

Model Evaluation & Human Ratings Significance for AI Products
Statistical rigor for ML/AI evaluation: comparing model performance, analyzing human ratings, detecting drift, and making defensible decisions. A comprehensive guide for AI practitioners and product teams.

Multiple Comparisons: When Bonferroni Is Too Conservative
A practical guide to controlling false positives when testing multiple hypotheses. Learn when Bonferroni over-corrects and better alternatives like Holm, FDR, and when to skip correction entirely.
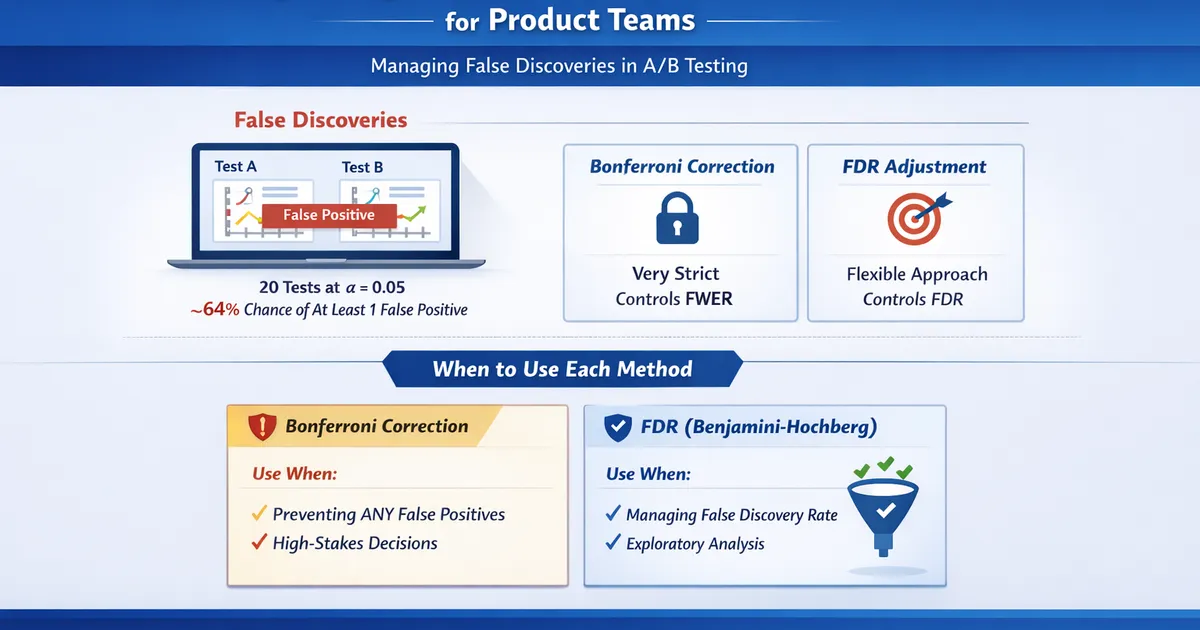
Multiple Experiments: FDR vs. Bonferroni for Product Teams
How to manage false discoveries when running many A/B tests simultaneously. Learn when to use Bonferroni, Benjamini-Hochberg FDR, and when corrections aren't needed.

Multiple Prompts and Metrics: Controlling False Discoveries in Evals
When evaluating models across many prompts or metrics, false positives multiply. Learn how to control false discovery rate and make defensible claims about model improvements.
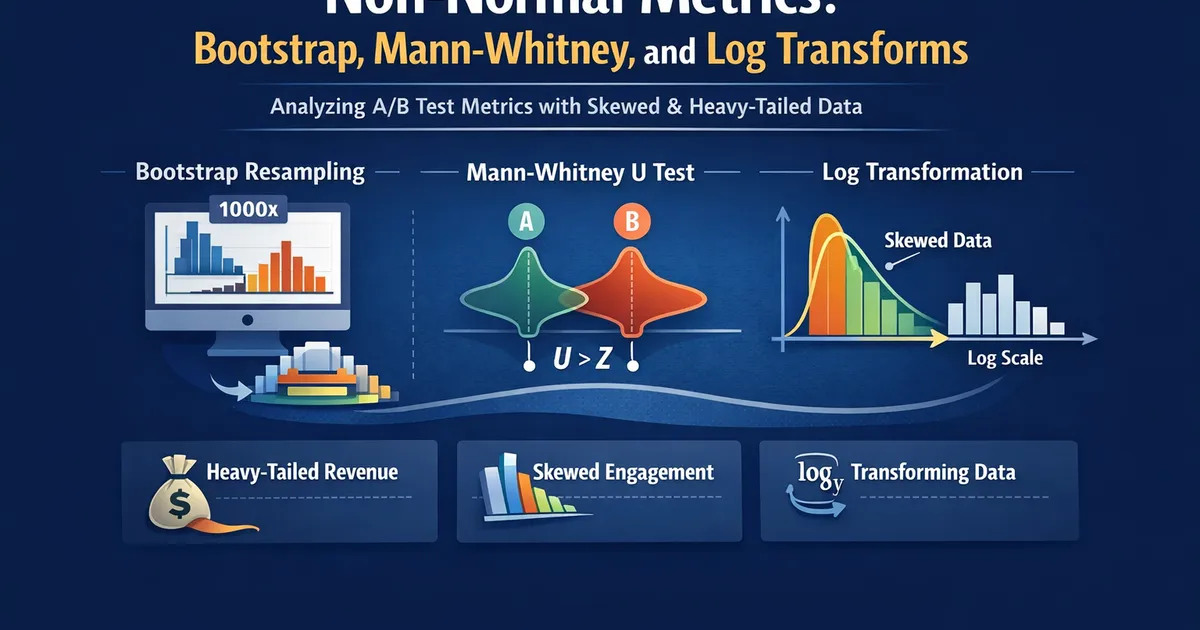
Non-Normal Metrics: Bootstrap, Mann-Whitney, and Log Transforms
How to analyze A/B test metrics that aren't normally distributed—heavy-tailed revenue, skewed engagement, and other messy real-world data. Covers bootstrap methods, Mann-Whitney U, and when transformations help.
Normality Tests Are Overrated: Better Diagnostics and Thresholds
Why formal normality tests like Shapiro-Wilk are problematic and what to use instead. Learn practical thresholds for when non-normality actually matters.

The One-Slide Experiment Readout: Five Numbers That Matter
A template for presenting experiment results in one slide. Focus on the five numbers executives actually need to make a decision.

One-Way ANOVA: Assumptions, Effect Sizes, and Proper Reporting
A practical guide to one-way ANOVA covering assumptions, diagnostics, effect size measures (eta-squared, omega-squared), and how to report results properly.
P-Values vs. Confidence Intervals: How to Interpret Both for Decisions
Understand the relationship between p-values and confidence intervals, when they agree, when they seem to disagree, and how to use them together for better decisions.

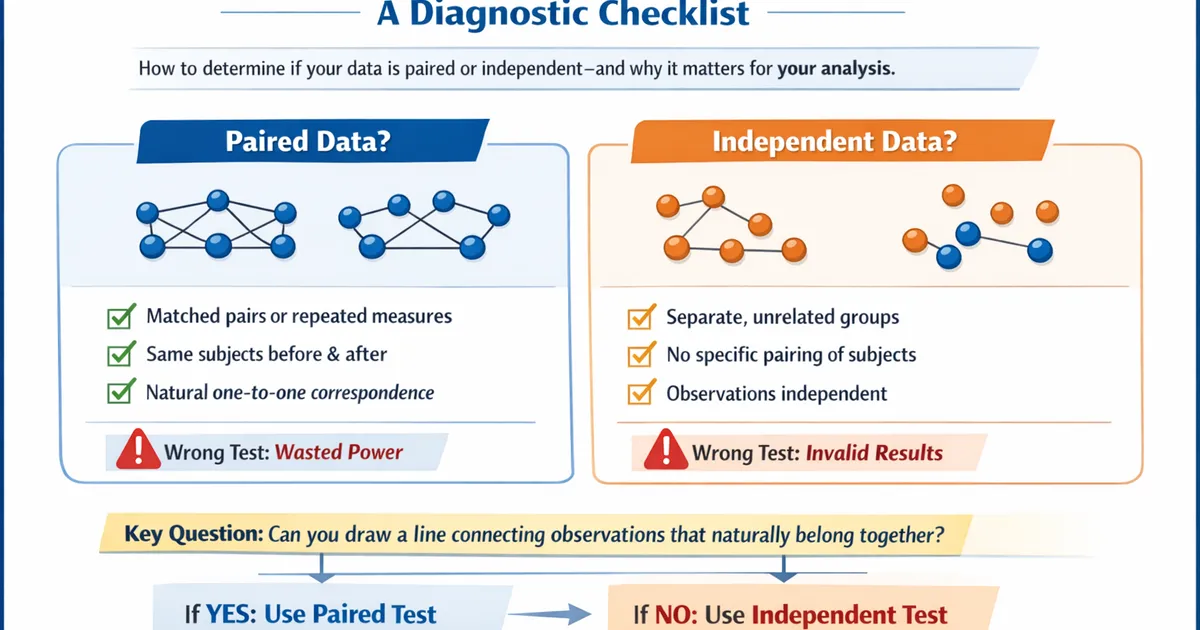
Paired Evaluation: McNemar's Test for Before/After Classification
When the same examples are evaluated by two models, use McNemar's test for proper inference. Learn why paired analysis is more powerful and how to implement it correctly.