Contents
Missing Data: MCAR, MAR, MNAR in Plain English and Practical Defaults
A practical guide to handling missing data. Learn the three types of missingness, why it matters for your analysis, and sensible default approaches for product analytics.
Quick Hits
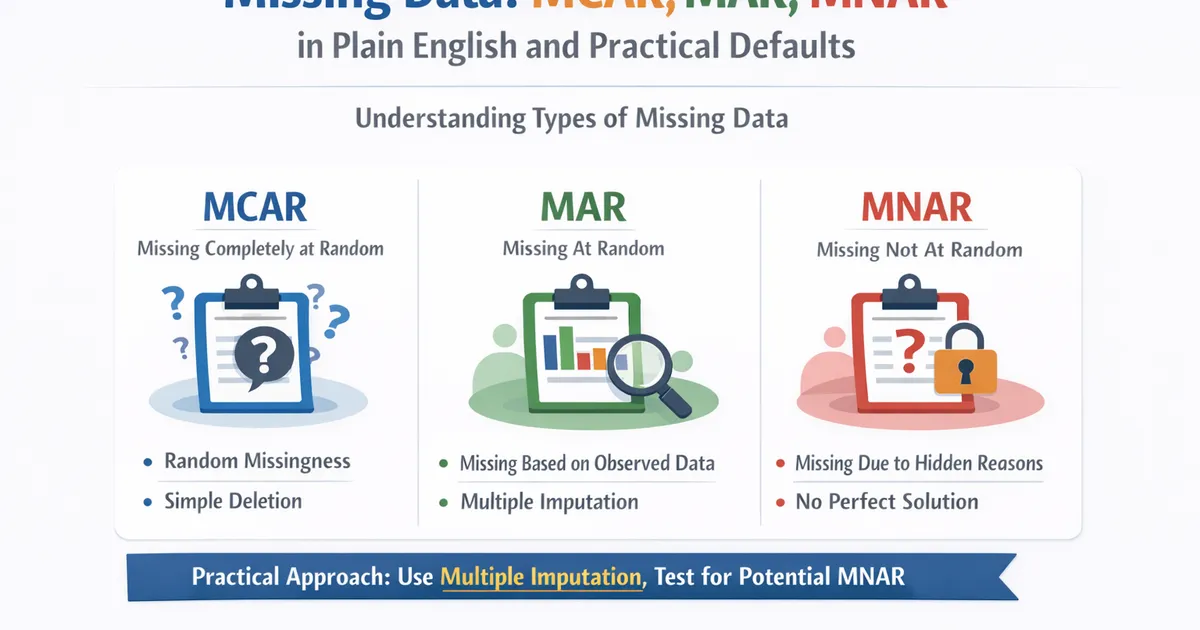
- •MCAR (completely random) is rare but allows simple deletion
- •MAR (random given observed data) is most common—use multiple imputation
- •MNAR (not random) is problematic—no perfect solution exists
- •Complete case analysis loses power and can bias results
TL;DR
Missing data isn't just missing—it matters why it's missing. MCAR (Missing Completely At Random) means missingness is pure chance and allows simple deletion. MAR (Missing At Random) means missingness depends on observed variables, requiring imputation. MNAR (Missing Not At Random) means missingness depends on the missing value itself—the hardest case with no perfect solution. Multiple imputation is a sensible default for most situations.
The Three Types of Missingness
In Plain English
MCAR (Missing Completely At Random). The probability of being missing is the same for everyone — like if your survey server randomly dropped 5% of responses. Example: random data transmission errors. Consequence: complete case analysis is OK (just loses power). Rare in practice.
MAR (Missing At Random). Missingness depends on OTHER variables you observed, but not on the missing value itself. Once you account for those variables, it's random. Example: older users are less likely to report income, but among same-age users, missingness doesn't depend on actual income level. Consequence: need imputation or adjustment using observed variables. Most common in practice.
MNAR (Missing Not At Random). Missingness depends on the missing value itself. People with high income might be less likely to report their income. Example: depressed patients are more likely to drop out of a depression study. Consequence: no statistical fix — need domain knowledge and sensitivity analysis. Common and problematic.
Simulation
import numpy as np
import pandas as pd
from scipy import stats
def simulate_missingness_types():
"""
Simulate and visualize the three types of missingness.
"""
np.random.seed(42)
n = 1000
# Full data
age = np.random.normal(40, 15, n)
income = 30000 + 1000 * age + np.random.normal(0, 20000, n)
income = np.maximum(income, 10000) # Floor at 10k
df = pd.DataFrame({'age': age, 'income': income})
# MCAR: Random 30% missing
df['income_mcar'] = df['income'].copy()
mcar_mask = np.random.random(n) < 0.3
df.loc[mcar_mask, 'income_mcar'] = np.nan
# MAR: Older people less likely to report (but not related to income itself)
mar_prob = 1 / (1 + np.exp(-(age - 50) / 10)) # Sigmoid based on age
mar_mask = np.random.random(n) < mar_prob
df['income_mar'] = df['income'].copy()
df.loc[mar_mask, 'income_mar'] = np.nan
# MNAR: High income people less likely to report
mnar_prob = 1 / (1 + np.exp(-(income - 80000) / 20000)) # Based on income
mnar_mask = np.random.random(n) < mnar_prob
df['income_mnar'] = df['income'].copy()
df.loc[mnar_mask, 'income_mnar'] = np.nan
# Compare
print("Impact of Different Missingness Types on Income Estimates:")
print("=" * 60)
print(f"\nTrue mean income: ${df['income'].mean():,.0f}")
print(f"True income SD: ${df['income'].std():,.0f}")
print()
print(f"{'Type':<8} {'Observed Mean':>15} {'Bias':>12} {'% Missing':>12}")
print("-" * 50)
for col, label in [('income_mcar', 'MCAR'),
('income_mar', 'MAR'),
('income_mnar', 'MNAR')]:
obs_mean = df[col].mean()
bias = obs_mean - df['income'].mean()
pct_missing = df[col].isna().mean() * 100
print(f"{label:<8} ${obs_mean:>13,.0f} ${bias:>+11,.0f} {pct_missing:>11.1f}%")
return df
df = simulate_missingness_types()
Diagnosing Missingness
Test for MCAR
def test_mcar(df, var_with_missing, other_vars):
"""
Test whether missingness is MCAR using t-tests.
Compare means of other variables between complete and incomplete cases.
"""
missing = df[var_with_missing].isna()
results = []
print(f"Testing if missingness in '{var_with_missing}' is MCAR:")
print("-" * 50)
for var in other_vars:
complete_cases = df.loc[~missing, var].dropna()
incomplete_cases = df.loc[missing, var].dropna()
if len(complete_cases) > 0 and len(incomplete_cases) > 0:
t_stat, p_val = stats.ttest_ind(complete_cases, incomplete_cases)
results.append({
'variable': var,
'mean_complete': complete_cases.mean(),
'mean_incomplete': incomplete_cases.mean(),
't_stat': t_stat,
'p_value': p_val
})
for r in results:
sig = "*" if r['p_value'] < 0.05 else ""
print(f"{r['variable']}: complete mean = {r['mean_complete']:.2f}, "
f"incomplete mean = {r['mean_incomplete']:.2f}, "
f"p = {r['p_value']:.4f}{sig}")
if any(r['p_value'] < 0.05 for r in results):
print("\n⚠️ Evidence against MCAR: missingness related to observed variables")
else:
print("\n✓ No evidence against MCAR (but MCAR not proven)")
return results
# Test our simulated data
test_mcar(df, 'income_mar', ['age'])
Visualize Missing Patterns
def visualize_missing_pattern(df, columns):
"""
Visualize patterns of missingness.
"""
# Create missing indicator matrix
missing_matrix = df[columns].isna().astype(int)
# Count patterns
patterns = missing_matrix.groupby(list(columns)).size().reset_index(name='count')
patterns = patterns.sort_values('count', ascending=False)
print("Missing Data Patterns:")
print("-" * 50)
print("(1 = missing, 0 = observed)")
print()
for _, row in patterns.head(10).iterrows():
pattern = ''.join(str(int(row[col])) for col in columns)
pct = row['count'] / len(df) * 100
bar = "█" * int(pct / 2)
print(f"{pattern}: {row['count']:>5} ({pct:>5.1f}%) {bar}")
return patterns
Handling Missing Data
Option 1: Complete Case Analysis (Listwise Deletion)
def complete_case_analysis(df, outcome_col, predictor_cols):
"""
Simple deletion of incomplete cases.
"""
# Drop rows with any missing values
complete_df = df[predictor_cols + [outcome_col]].dropna()
print("Complete Case Analysis:")
print("-" * 40)
print(f"Original n: {len(df)}")
print(f"Complete cases: {len(complete_df)} ({len(complete_df)/len(df)*100:.1f}%)")
print(f"Cases deleted: {len(df) - len(complete_df)}")
if len(complete_df) / len(df) < 0.7:
print("\n⚠️ Warning: >30% of data deleted")
print(" Consider imputation to preserve power and reduce potential bias")
return complete_df
def demonstrate_deletion_bias():
"""
Show how deletion can bias results under MAR/MNAR.
"""
np.random.seed(42)
n = 500
# True relationship: y = 10 + 2*x + error
x = np.random.normal(50, 10, n)
y = 10 + 2 * x + np.random.normal(0, 20, n)
# MAR: missingness in y depends on x
# Higher x → more likely to be missing
miss_prob = 1 / (1 + np.exp(-(x - 55) / 5))
missing = np.random.random(n) < miss_prob
y_observed = y.copy()
y_observed[missing] = np.nan
# True regression
from scipy.stats import linregress
true_slope, true_intercept, _, _, _ = linregress(x, y)
# Complete case regression
complete_mask = ~missing
cc_slope, cc_intercept, _, _, _ = linregress(x[complete_mask], y[complete_mask])
print("Bias from Complete Case Analysis (MAR scenario):")
print("-" * 50)
print(f"True slope: {true_slope:.3f}")
print(f"Complete case slope: {cc_slope:.3f}")
print(f"Bias: {cc_slope - true_slope:.3f} ({(cc_slope-true_slope)/true_slope*100:.1f}%)")
demonstrate_deletion_bias()
Option 2: Simple Imputation (Not Recommended)
def demonstrate_simple_imputation_problems():
"""
Show why simple mean imputation is problematic.
"""
np.random.seed(42)
# Original data
data = np.random.normal(100, 20, 100)
true_mean = np.mean(data)
true_std = np.std(data, ddof=1)
# Create 30% missing
missing_mask = np.random.random(100) < 0.3
data_with_missing = data.copy()
data_with_missing[missing_mask] = np.nan
# Mean imputation
observed_mean = np.nanmean(data_with_missing)
imputed = np.where(missing_mask, observed_mean, data)
print("Problems with Mean Imputation:")
print("-" * 50)
print(f"\n{'Statistic':<20} {'True':>12} {'Mean Imputed':>15}")
print("-" * 50)
print(f"{'Mean':<20} {true_mean:>12.2f} {np.mean(imputed):>15.2f}")
print(f"{'Std Dev':<20} {true_std:>12.2f} {np.std(imputed, ddof=1):>15.2f}")
print(f"{'Variance':<20} {true_std**2:>12.2f} {np.var(imputed, ddof=1):>15.2f}")
print()
print("Problem: Mean imputation underestimates variance")
print(" Standard errors are too small")
print(" CIs are too narrow")
print(" P-values are too small")
demonstrate_simple_imputation_problems()
Option 3: Multiple Imputation (Recommended)
Step 1: Create M imputed datasets (typically 5-20). Each dataset fills in missing values differently, sampling from the predictive distribution.
Step 2: Analyze each imputed dataset separately. Get M sets of estimates and standard errors.
Step 3: Combine results using Rubin's rules:
- Point estimate = average of M estimates
- Variance = within-imputation + between-imputation
Why it works:
- Preserves variability (unlike mean imputation)
- Properly accounts for uncertainty due to missing data
- Produces valid standard errors and CIs
def simple_multiple_imputation(df, target_col, predictor_cols, m=5):
"""
Simplified multiple imputation for illustration.
"""
from sklearn.linear_model import LinearRegression
# Identify complete and incomplete cases
complete = df.dropna()
incomplete_mask = df[target_col].isna()
if not incomplete_mask.any():
return df[target_col].values
# Fit model on complete cases
X_complete = complete[predictor_cols].values
y_complete = complete[target_col].values
model = LinearRegression()
model.fit(X_complete, y_complete)
# Predict for incomplete cases
X_incomplete = df.loc[incomplete_mask, predictor_cols].values
predictions = model.predict(X_incomplete)
# Estimate residual variance
residuals = y_complete - model.predict(X_complete)
residual_std = np.std(residuals, ddof=len(predictor_cols) + 1)
# Generate m imputed datasets
imputed_datasets = []
for _ in range(m):
# Add random noise to predictions
imputed_values = predictions + np.random.normal(0, residual_std, len(predictions))
full_data = df[target_col].copy()
full_data.loc[incomplete_mask] = imputed_values
imputed_datasets.append(full_data.values)
return imputed_datasets
def analyze_with_multiple_imputation(df, target_col, predictor_cols, m=10):
"""
Complete MI analysis.
"""
imputed_datasets = simple_multiple_imputation(df, target_col, predictor_cols, m)
# Analyze each imputed dataset
means = []
variances = []
for imputed in imputed_datasets:
means.append(np.mean(imputed))
variances.append(np.var(imputed, ddof=1) / len(imputed))
# Combine using Rubin's rules
combined_mean = np.mean(means)
# Within-imputation variance
within_var = np.mean(variances)
# Between-imputation variance
between_var = np.var(means, ddof=1)
# Total variance
total_var = within_var + (1 + 1/m) * between_var
return {
'estimate': combined_mean,
'se': np.sqrt(total_var),
'within_var': within_var,
'between_var': between_var,
'm': m
}
Practical Recommendations
Decision Framework
What is the proportion of missing data?
│
├── < 5%
│ └── Complete case analysis usually OK
│ (unless MNAR is likely)
│
├── 5-20%
│ └── Use multiple imputation
│ Test sensitivity to missing data mechanism
│
├── 20-40%
│ └── Multiple imputation essential
│ Strong sensitivity analysis needed
│
└── > 40%
└── Seriously question data quality
Consider the variable unreliable
Best Practices
1. Report it
- Do: report % missing for each variable, describe patterns of missingness, explain your handling strategy
- Don't: silently drop missing cases, ignore the issue in your write-up
2. Investigate it
- Do: test for MCAR using Little's test or comparisons, look for predictors of missingness, consider domain knowledge about WHY data is missing
- Don't: assume MCAR without checking, ignore obvious patterns
3. Handle it appropriately
- Do: use multiple imputation for MAR, include auxiliary variables in imputation model, run sensitivity analyses for MNAR
- Don't: use single mean imputation, impute outcome in experiments (can bias treatment effect), over-complicate when missing rate is low
4. Be transparent
- Do: report results with and without imputation, acknowledge limitations, discuss potential MNAR scenarios
- Don't: cherry-pick the analysis that looks better, claim imputation "fixed" the problem
R Implementation
# Missing data analysis in R
library(mice) # Multiple imputation
library(naniar) # Missing data visualization
# Visualize missing patterns
vis_miss(df)
gg_miss_upset(df)
# Test MCAR
library(MissMech)
TestMCARNormality(df)
# Multiple imputation with mice
imp <- mice(df, m = 10, method = 'pmm', seed = 42)
# Analyze each imputed dataset
fit <- with(imp, lm(outcome ~ predictor1 + predictor2))
# Pool results using Rubin's rules
pooled <- pool(fit)
summary(pooled)
# Compare complete case vs MI
cc_fit <- lm(outcome ~ predictor1 + predictor2, data = na.omit(df))
summary(cc_fit)
summary(pooled)
Sensitivity Analysis for MNAR
def mnar_sensitivity_analysis(df, target_col, shift_values=[-10, -5, 0, 5, 10]):
"""
Simple sensitivity analysis for potential MNAR.
Assume missing values are systematically different.
"""
observed_mean = df[target_col].dropna().mean()
print("MNAR Sensitivity Analysis:")
print("-" * 50)
print(f"Observed mean (complete cases): {observed_mean:.2f}")
print()
print(f"If missing values were systematically different:")
print()
print(f"{'Shift':>10} {'Imputed Mean':>15} {'Overall Mean':>15}")
print("-" * 45)
n_total = len(df)
n_missing = df[target_col].isna().sum()
n_observed = n_total - n_missing
for shift in shift_values:
imputed_missing_mean = observed_mean + shift
overall_mean = (observed_mean * n_observed +
imputed_missing_mean * n_missing) / n_total
print(f"{shift:>+10} {imputed_missing_mean:>15.2f} {overall_mean:>15.2f}")
# Example
np.random.seed(42)
data = pd.DataFrame({
'value': np.concatenate([np.random.normal(100, 20, 70), [np.nan] * 30])
})
mnar_sensitivity_analysis(data, 'value')
Related Methods
- Assumption Checks Master Guide — The pillar article
- Pre-Analysis Checklist — Complete data prep checklist
- Audit Trails — Documenting data decisions
Key Takeaway
Missing data handling depends on WHY data is missing. MCAR (completely random) allows simple deletion but is rare. MAR (predictable from observed data) requires multiple imputation to avoid bias. MNAR (depends on the missing value) has no perfect solution—use sensitivity analysis. Default to multiple imputation, be transparent about missing data, and always report how you handled it.
References
- https://www.jstor.org/stable/2290157
- https://doi.org/10.1146/annurev.psych.58.110405.085530
- Rubin, D. B. (1976). Inference and missing data. *Biometrika*, 63(3), 581-592.
- Schafer, J. L., & Graham, J. W. (2002). Missing data: Our view of the state of the art. *Psychological Methods*, 7(2), 147-177.
- Little, R. J., & Rubin, D. B. (2019). *Statistical Analysis with Missing Data* (3rd ed.). Wiley.
Frequently Asked Questions
Can I just delete rows with missing data?
What's the best imputation method?
How do I know what type of missingness I have?
Key Takeaway
Missing data handling depends on WHY the data is missing. MCAR (completely random) allows simple deletion but is rare. MAR (random given observed variables) requires multiple imputation or similar methods. MNAR (related to the missing value itself) has no perfect solution. The default approach should be multiple imputation, with sensitivity analysis for potential MNAR.