StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.
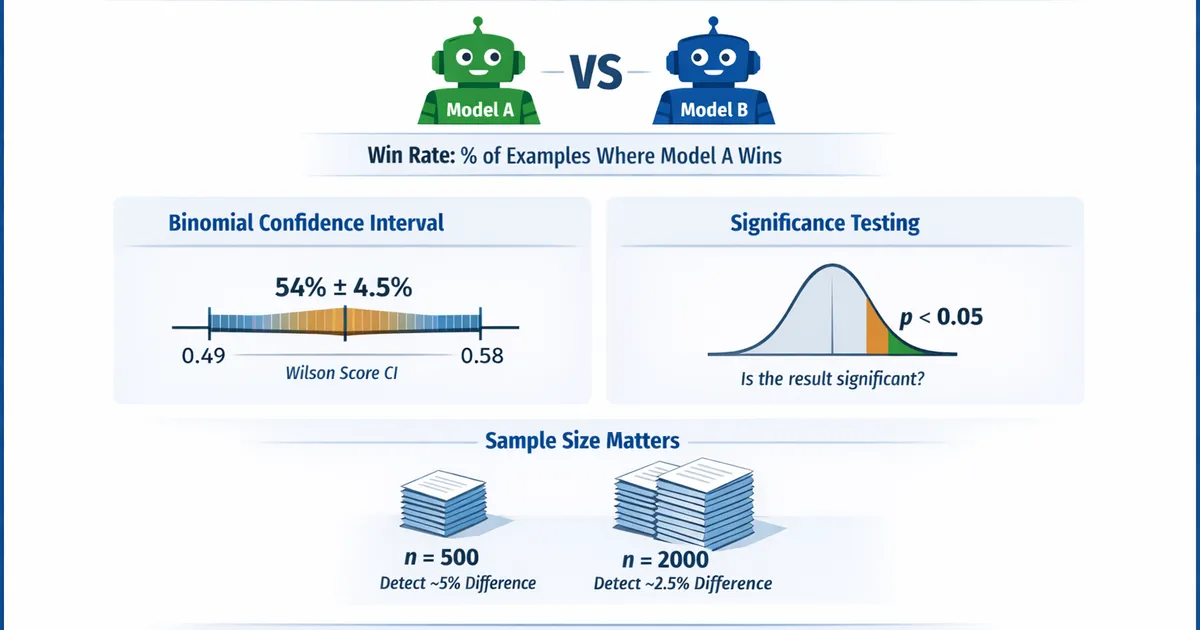
Comparing Two Models: Win Rate, Binomial CI, and Proper Tests
How to rigorously compare two ML models using win rate analysis. Learn about binomial confidence intervals, significance tests, and how many examples you actually need.
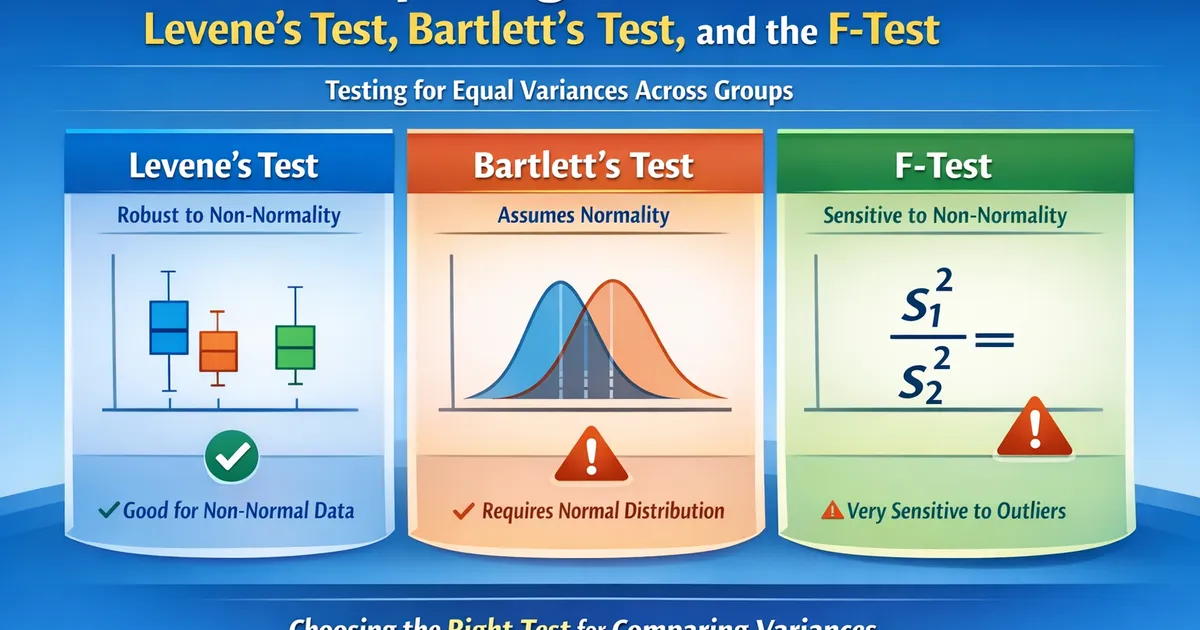
Comparing Variances: Levene's Test, Bartlett's Test, and the F-Test
When you need to test whether two or more groups have equal variances. Covers Levene's test, Bartlett's test, Brown-Forsythe, and when each is appropriate.
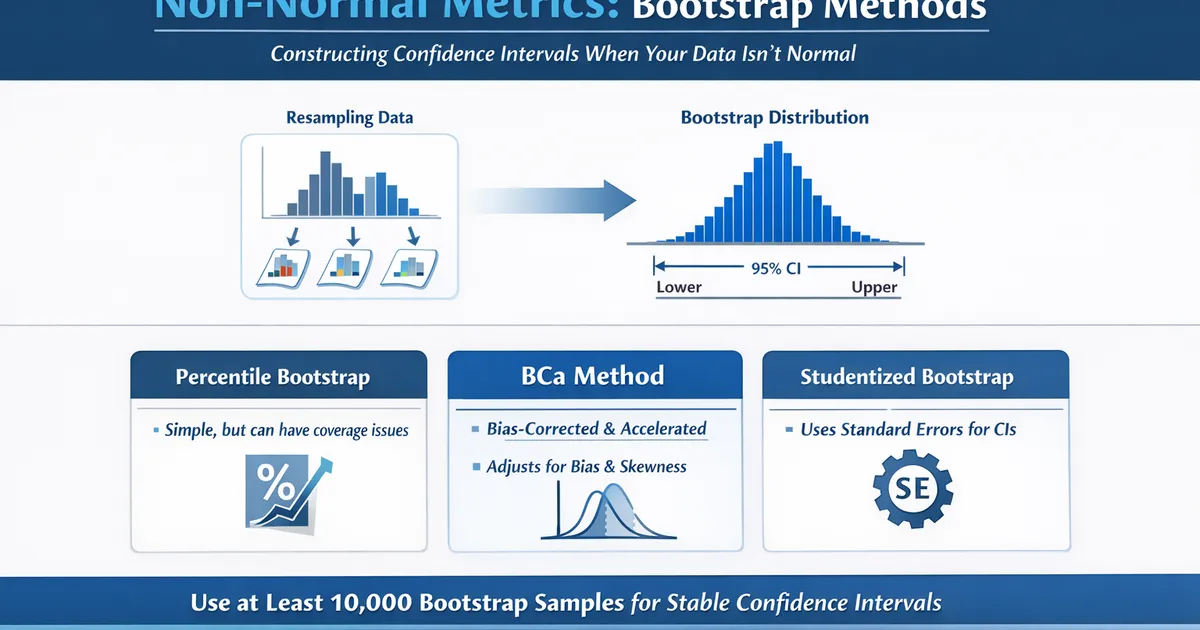
Confidence Intervals for Non-Normal Metrics: Bootstrap Methods
How to construct confidence intervals when your data isn't normal. Covers percentile, BCa, and studentized bootstrap methods with practical guidance on when each works best.
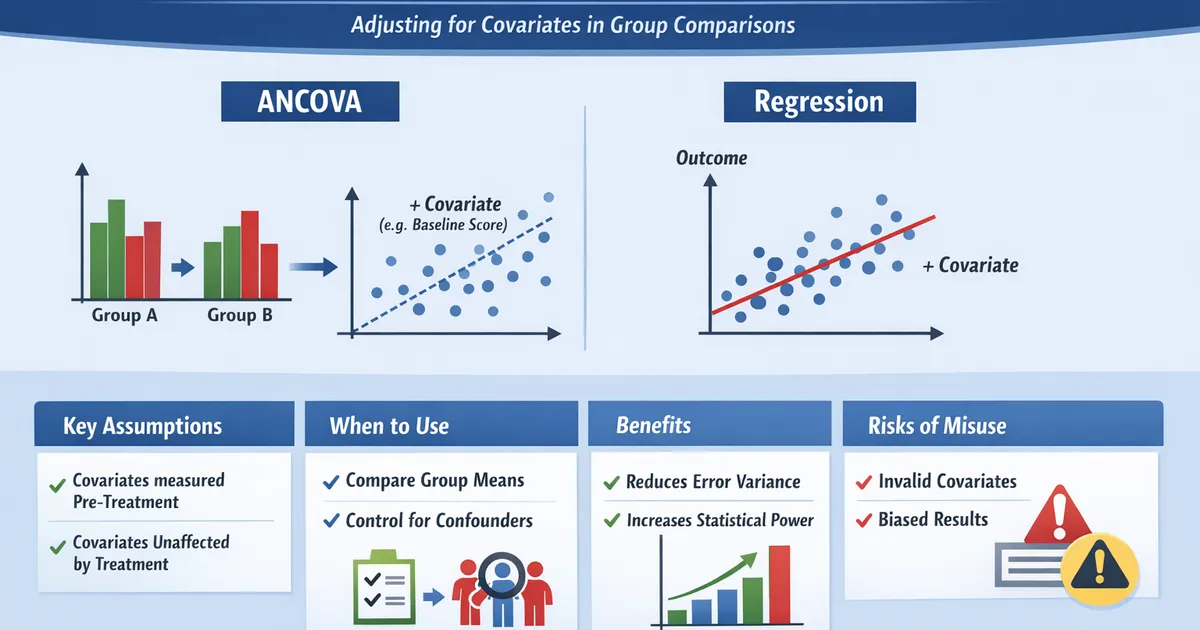
Controlling for Covariates: ANCOVA vs. Regression
When and how to control for covariates in group comparisons. Covers ANCOVA, regression adjustment, and the key assumptions that make covariate adjustment valid.

Cox Proportional Hazards: What 'Proportional' Actually Means
A practical guide to Cox regression for product analysts. Learn what the proportional hazards assumption means, how to check it, what to do when it fails, and how to interpret hazard ratios correctly.
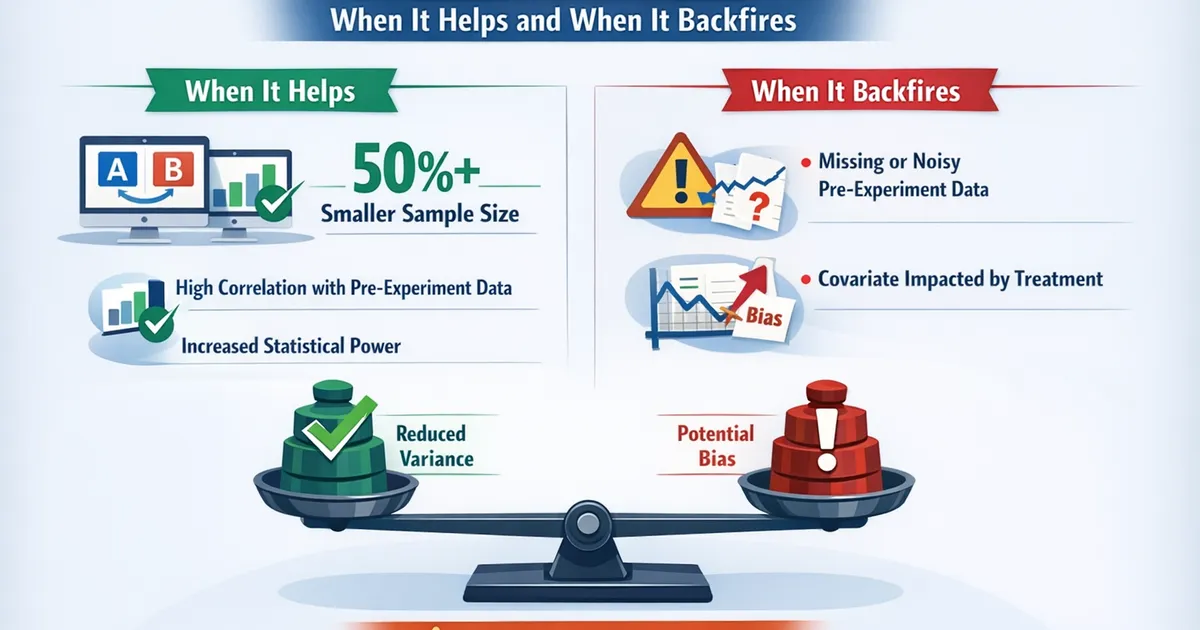
CUPED and Variance Reduction: When It Helps and When It Backfires
Learn how CUPED (Controlled-experiment Using Pre-Experiment Data) can dramatically reduce variance in A/B tests, when to use it, and the pitfalls that can make it backfire.
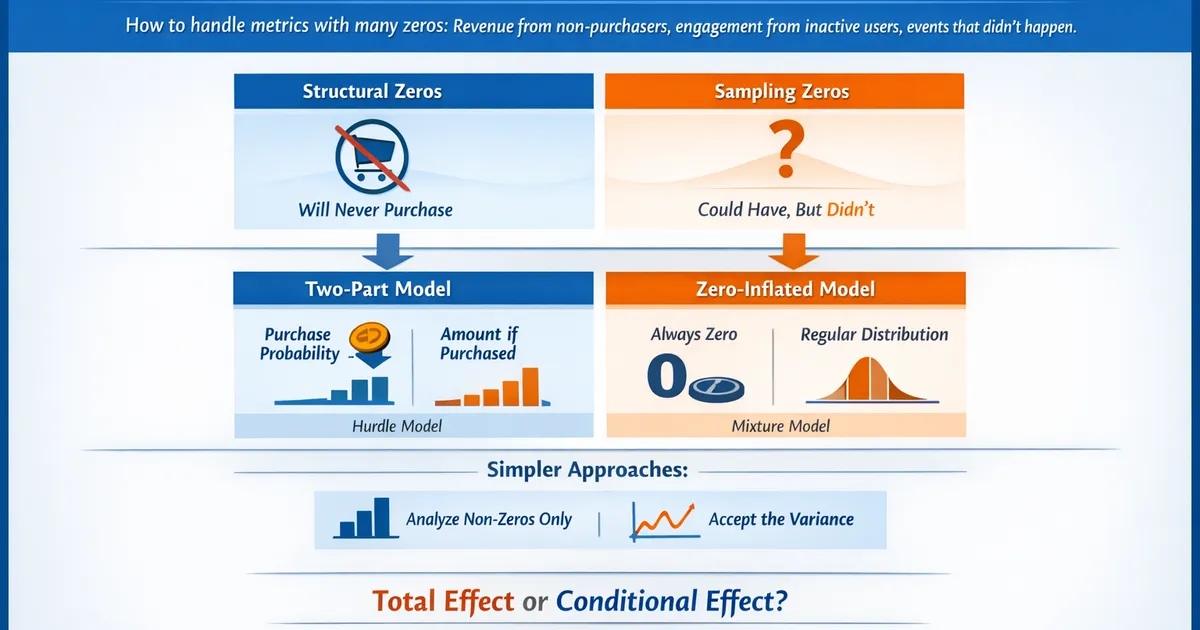
Dealing with Zeros: Zero-Inflated and Two-Part Models
How to handle metrics with many zeros—revenue from non-purchasers, engagement from inactive users, events that didn't happen. Learn when to use zero-inflated models, two-part models, and simpler alternatives.
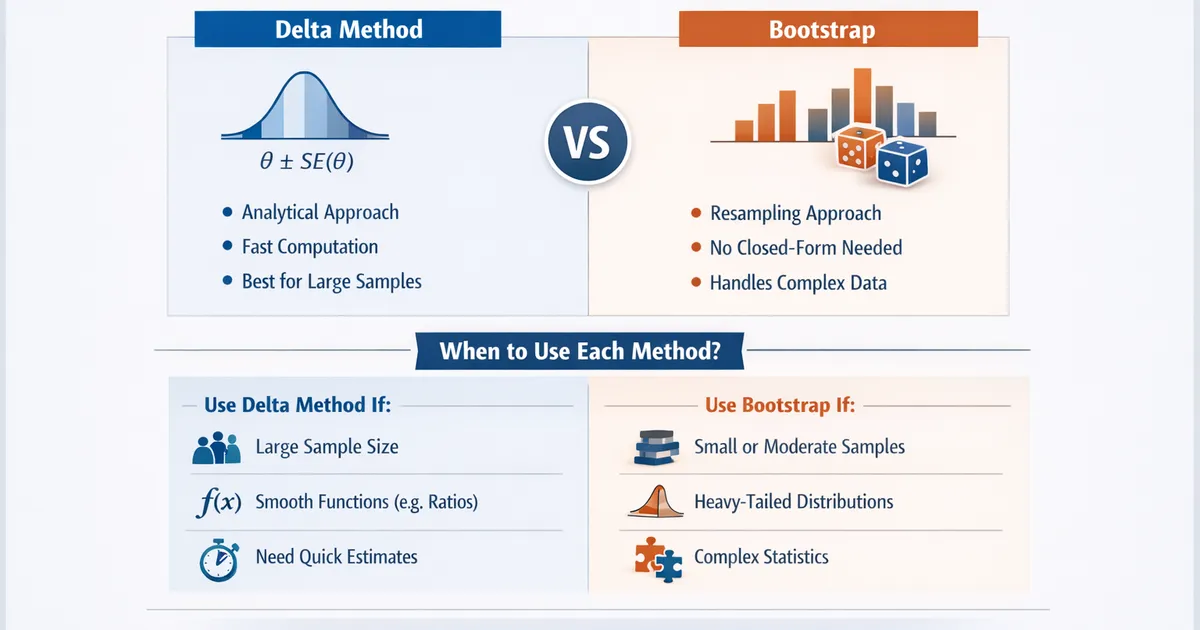
Delta Method vs. Bootstrap: When Each Is Appropriate
A practical guide to choosing between delta method and bootstrap for variance estimation. Learn when each approach excels, their assumptions, and how to implement both.

Drift Detection: KS Test, PSI, and Interpreting Signals
How to detect when your model's inputs or outputs have shifted. Learn about KS tests, Population Stability Index, and when drift actually matters.

Effect Sizes for Mean Differences: Cohen's d, Hedges' g, and Raw Differences
A practical guide to effect sizes for comparing means. Learn when to use standardized vs. raw effect sizes, how to calculate and interpret them, and how to report them properly.
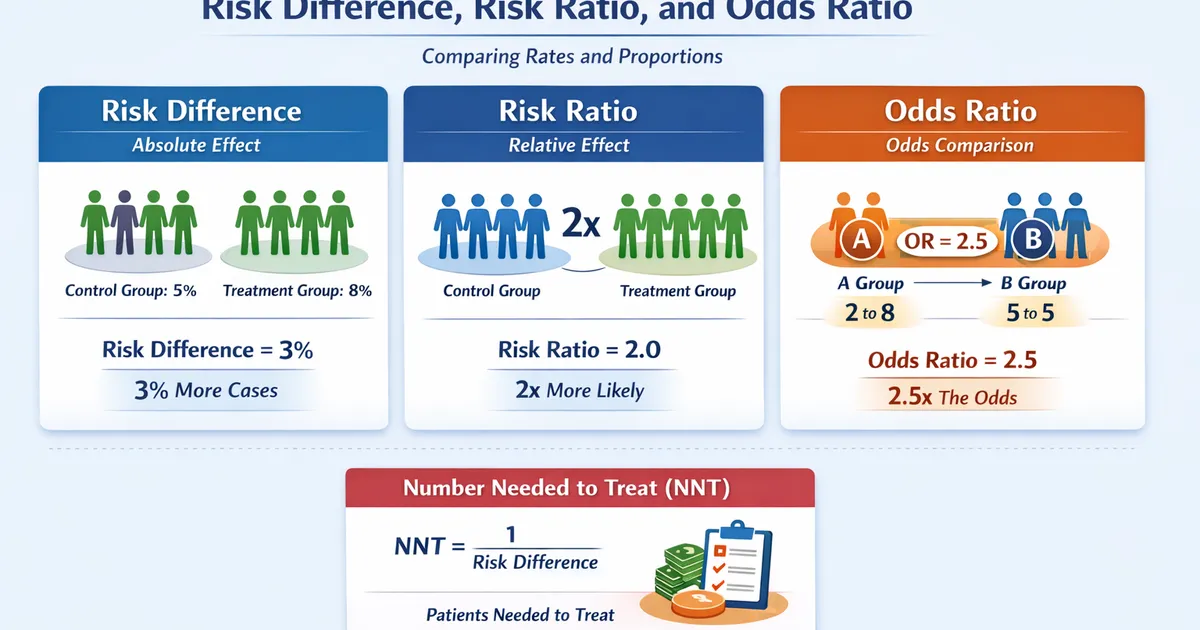
Effect Sizes for Proportions: Risk Difference, Risk Ratio, and Odds Ratio
A practical guide to effect sizes when comparing rates and proportions. Learn when to use risk difference vs. risk ratio vs. odds ratio, and how to interpret each correctly.