StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.

Bootstrap for Metric Deltas: AUC, F1, and Other ML Metrics
How to compute confidence intervals and p-values for differences in ML metrics like AUC, F1, and precision. Learn paired bootstrap for defensible model comparisons.

Calibration Checks: Brier Score and Reliability Diagrams
A model can have high accuracy but terrible probability estimates. Learn how to assess calibration with Brier score, ECE, and reliability diagrams.
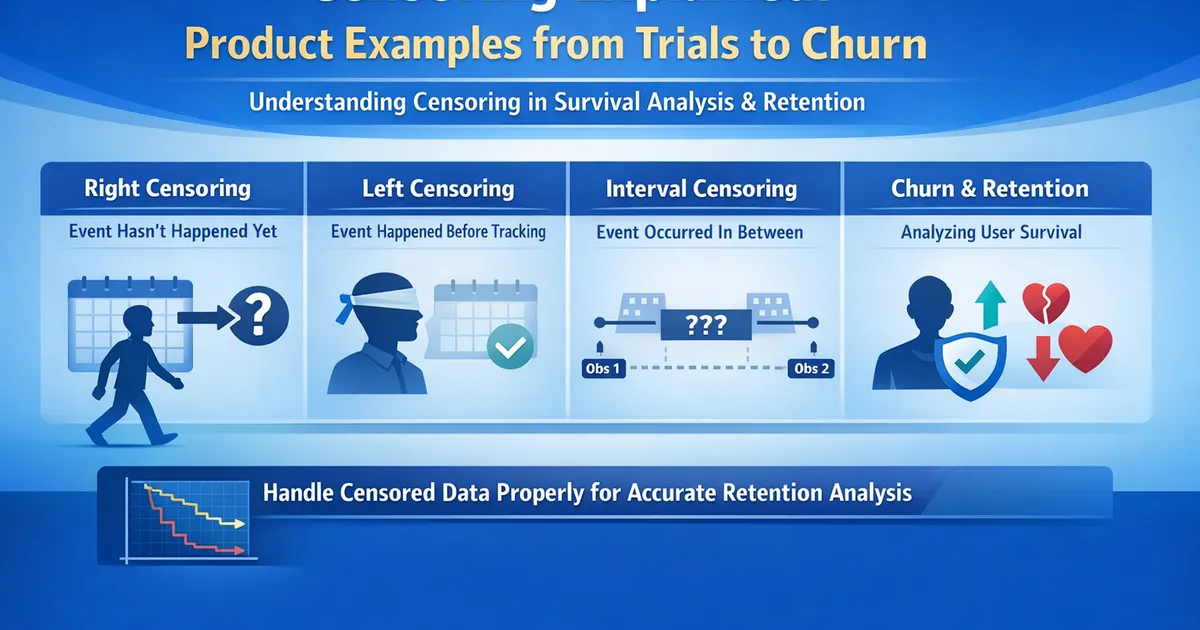
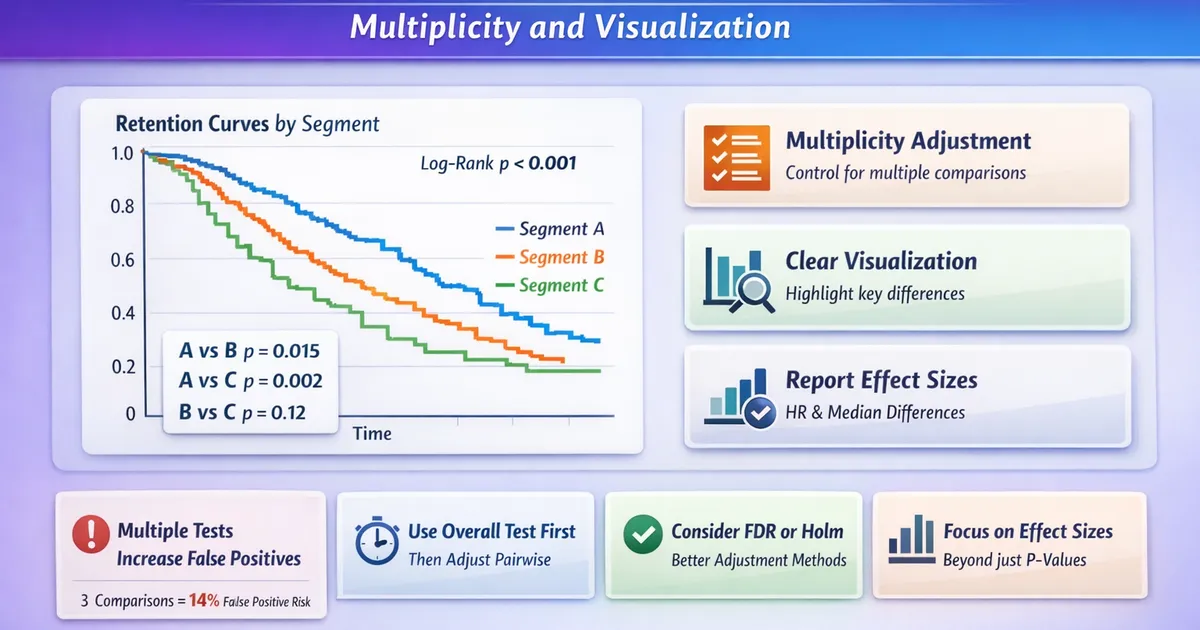
Censoring Explained: Product Examples from Trials to Churn
A practical guide to understanding censoring in survival analysis. Learn the different types of censoring, why it matters for retention analysis, and how to identify and handle censoring in your product data.
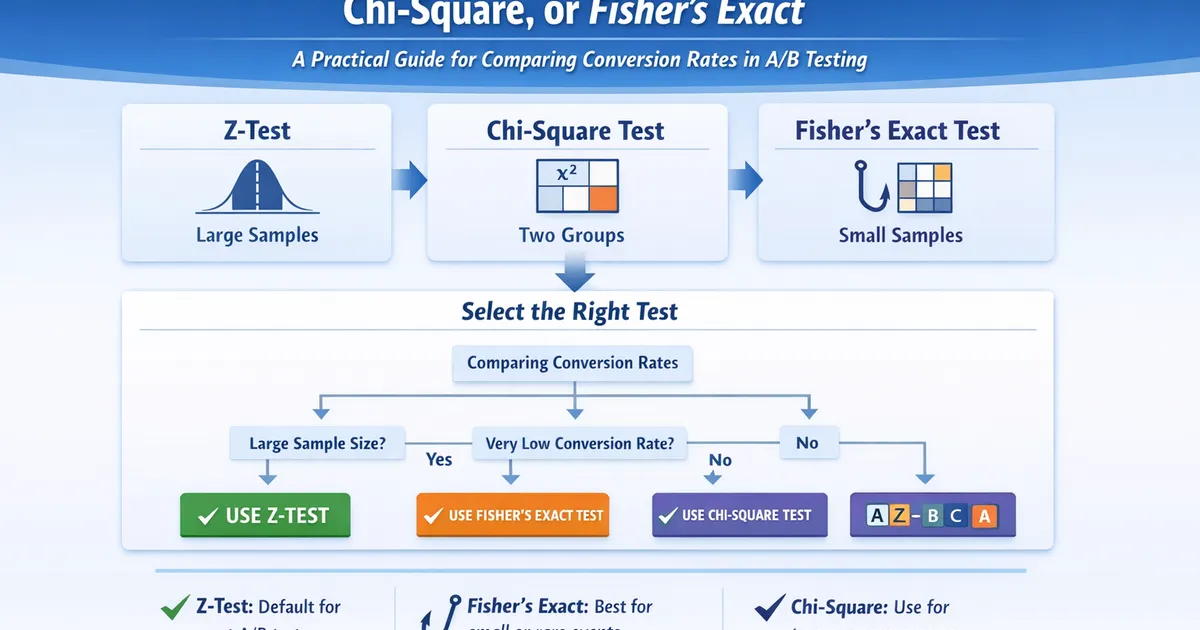
Choosing the Right Test for Conversion Rates: Z-Test, Chi-Square, or Fisher's Exact
A practical decision framework for selecting between z-test, chi-square test, and Fisher's exact test when comparing conversion rates in A/B experiments.

Clustered Experiments: Geo Tests, Classrooms, and Independence Violations
How to handle A/B tests where observations aren't independent—geo experiments, marketplace tests, social features, and other settings where users are clustered or connected.
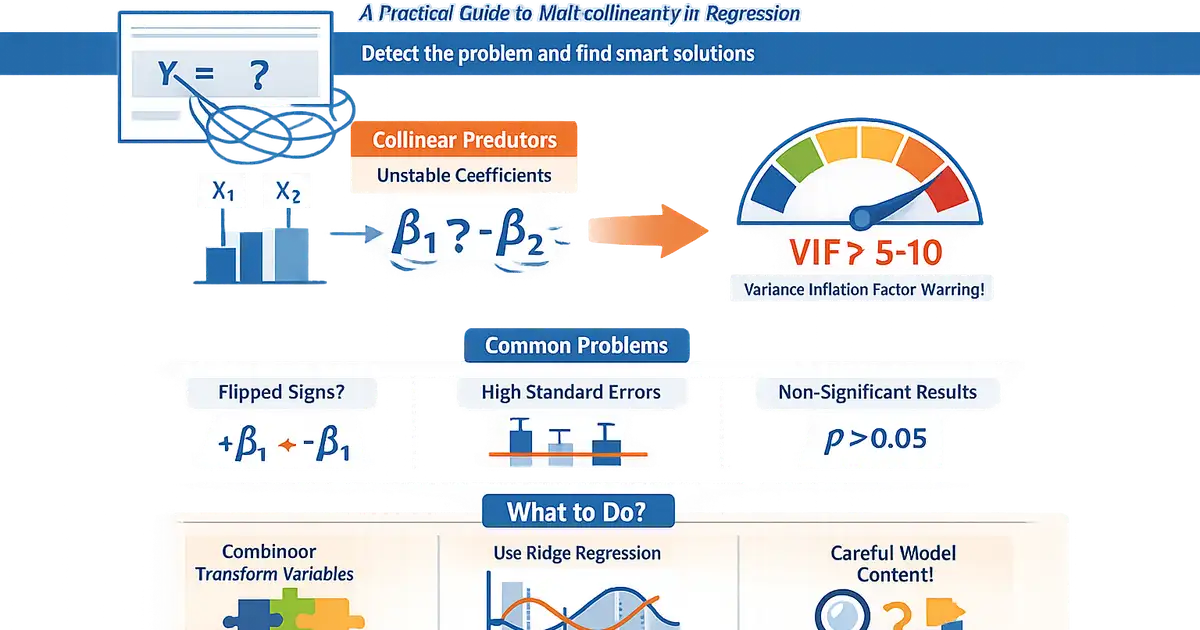
Collinearity: When It Breaks Interpretation and What to Do
A practical guide to multicollinearity in regression. Learn when collinearity is a problem, how to detect it, and practical solutions that don't involve blindly dropping variables.

Common Analyst Mistakes: P-Hacking, Metric Slicing, and Post-Hoc Stories
A field guide to the statistical mistakes that destroy credibility. Learn to recognize p-hacking, cherry-picking segments, and post-hoc rationalization—in your own work and others'.

How to Communicate Uncertainty to Execs Without Losing the Room
Frameworks for presenting statistical uncertainty to non-technical stakeholders. Say 'we're not sure' without losing credibility or decision-making momentum.
Comparing ARPU and ARPPU: Segmentation vs. Modeling Approaches
How to properly analyze revenue per user metrics in A/B tests. Learn the statistical pitfalls of ARPU vs. ARPPU, when to segment, and how to avoid Simpson's paradox.

Comparing Medians: Statistical Tests and Better Options
When you need to compare medians instead of means, standard tests often fall short. Learn about Mood's median test, quantile regression, and bootstrap methods for proper median comparison.

Comparing Rates: Events per User, Events per Time, and Rate Ratios
How to properly compare rates like clicks per user, purchases per session, or events per hour. Covers rate ratios, Poisson tests, and common pitfalls with ratio metrics.