StatsTest Blog
Experimental design, data analysis, and statistical tooling for modern teams. No hype, just the math.

Common Analyst Mistakes: P-Hacking, Metric Slicing, and Post-Hoc Stories
A field guide to the statistical mistakes that destroy credibility. Learn to recognize p-hacking, cherry-picking segments, and post-hoc rationalization—in your own work and others'.

How to Communicate Uncertainty to Execs Without Losing the Room
Frameworks for presenting statistical uncertainty to non-technical stakeholders. Say 'we're not sure' without losing credibility or decision-making momentum.
Comparing ARPU and ARPPU: Segmentation vs. Modeling Approaches
How to properly analyze revenue per user metrics in A/B tests. Learn the statistical pitfalls of ARPU vs. ARPPU, when to segment, and how to avoid Simpson's paradox.

Comparing Medians: Statistical Tests and Better Options
When you need to compare medians instead of means, standard tests often fall short. Learn about Mood's median test, quantile regression, and bootstrap methods for proper median comparison.
Comparing More Than Two Groups: A Complete Guide
How to compare means, medians, and distributions across three or more groups. Covers ANOVA, Kruskal-Wallis, post-hoc tests, and when each method is appropriate.

Comparing Rates: Events per User, Events per Time, and Rate Ratios
How to properly compare rates like clicks per user, purchases per session, or events per hour. Covers rate ratios, Poisson tests, and common pitfalls with ratio metrics.
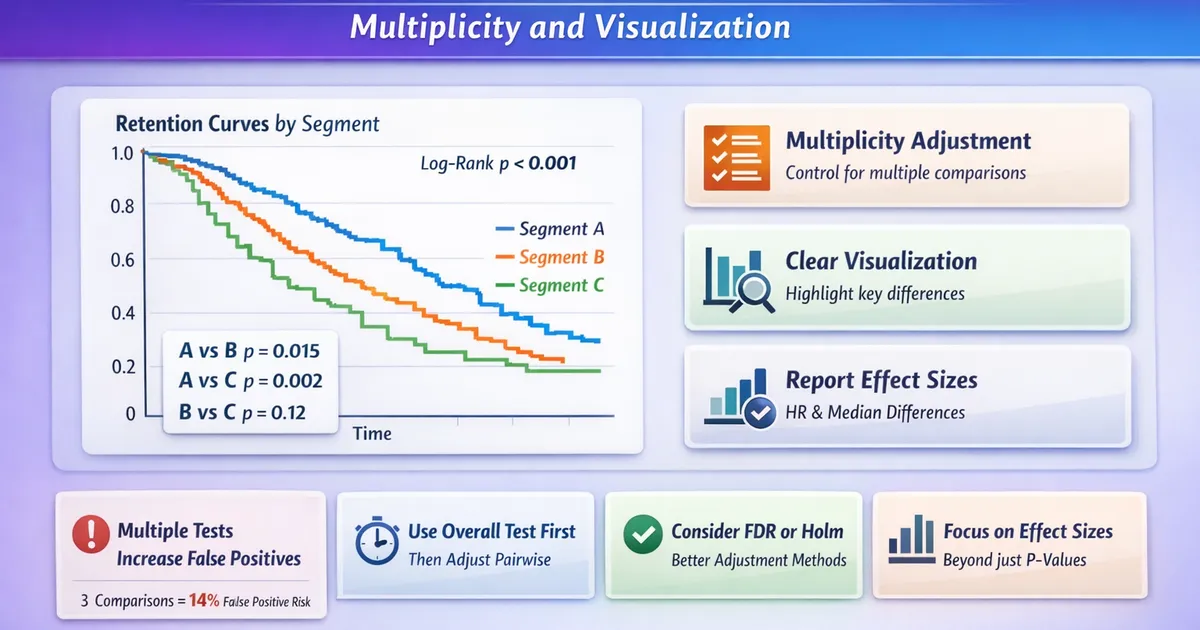
Comparing Retention Curves Across Segments: Multiplicity and Visualization
A practical guide to comparing survival curves across multiple segments. Learn how to visualize multiple retention curves, handle multiple comparisons, and communicate segment differences clearly.
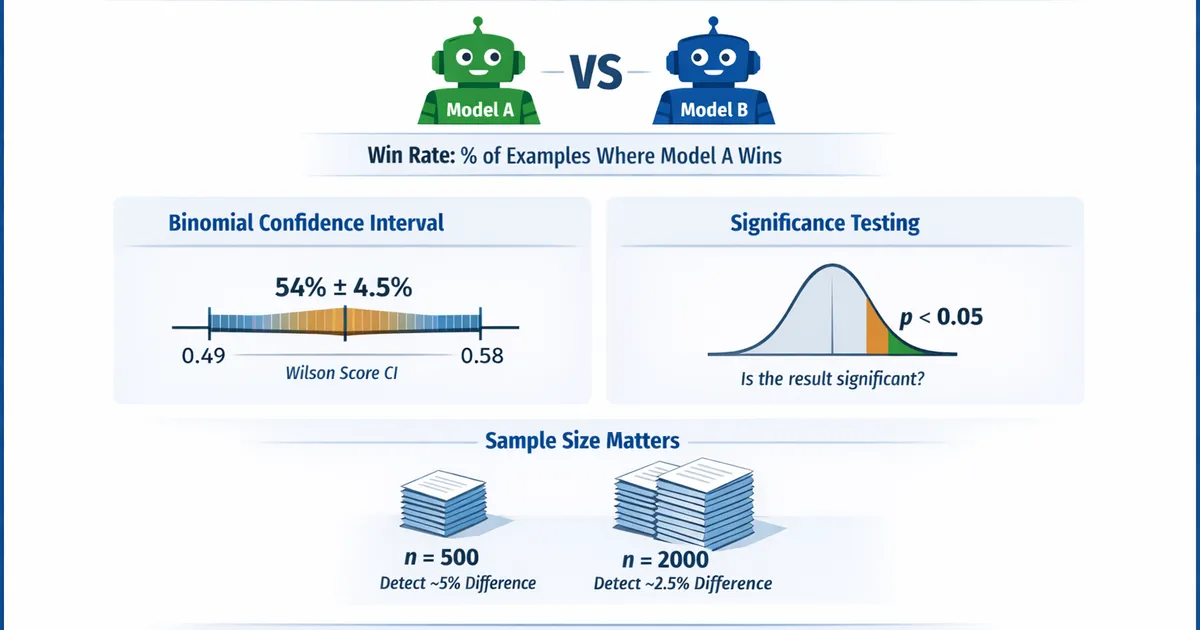
Comparing Two Models: Win Rate, Binomial CI, and Proper Tests
How to rigorously compare two ML models using win rate analysis. Learn about binomial confidence intervals, significance tests, and how many examples you actually need.
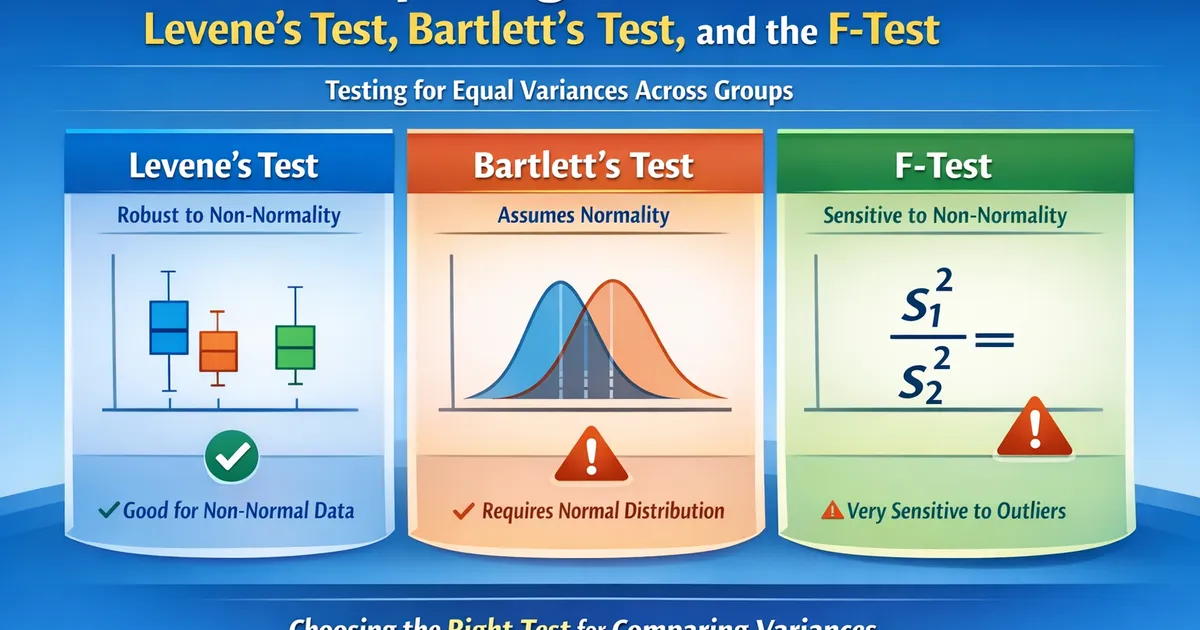
Comparing Variances: Levene's Test, Bartlett's Test, and the F-Test
When you need to test whether two or more groups have equal variances. Covers Levene's test, Bartlett's test, Brown-Forsythe, and when each is appropriate.
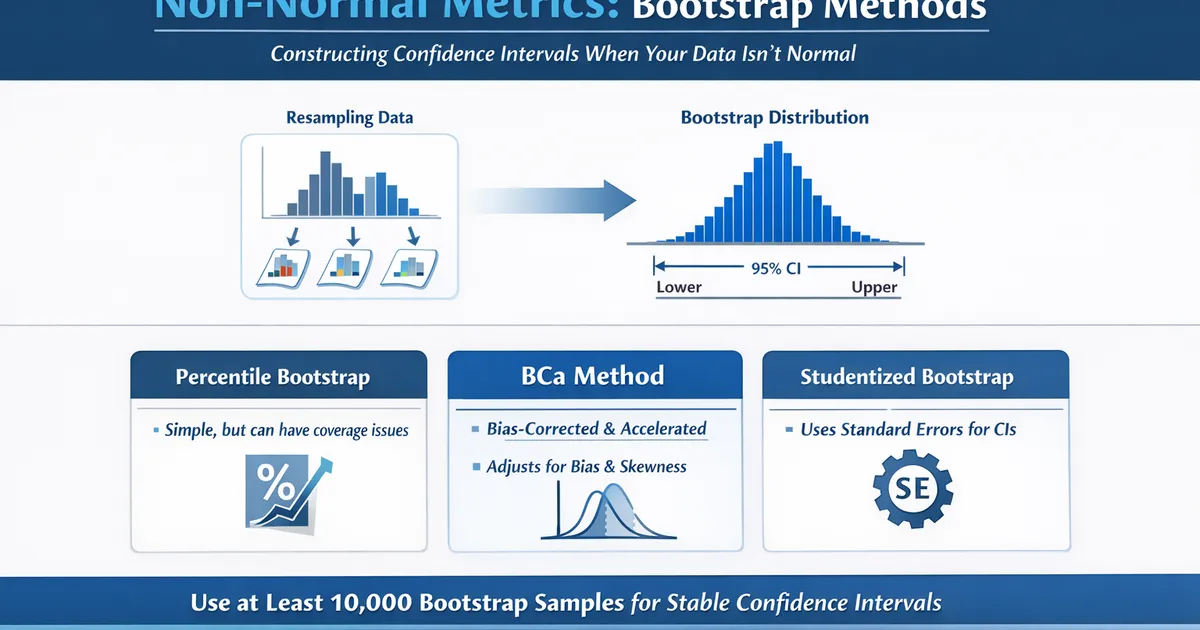
Confidence Intervals for Non-Normal Metrics: Bootstrap Methods
How to construct confidence intervals when your data isn't normal. Covers percentile, BCa, and studentized bootstrap methods with practical guidance on when each works best.
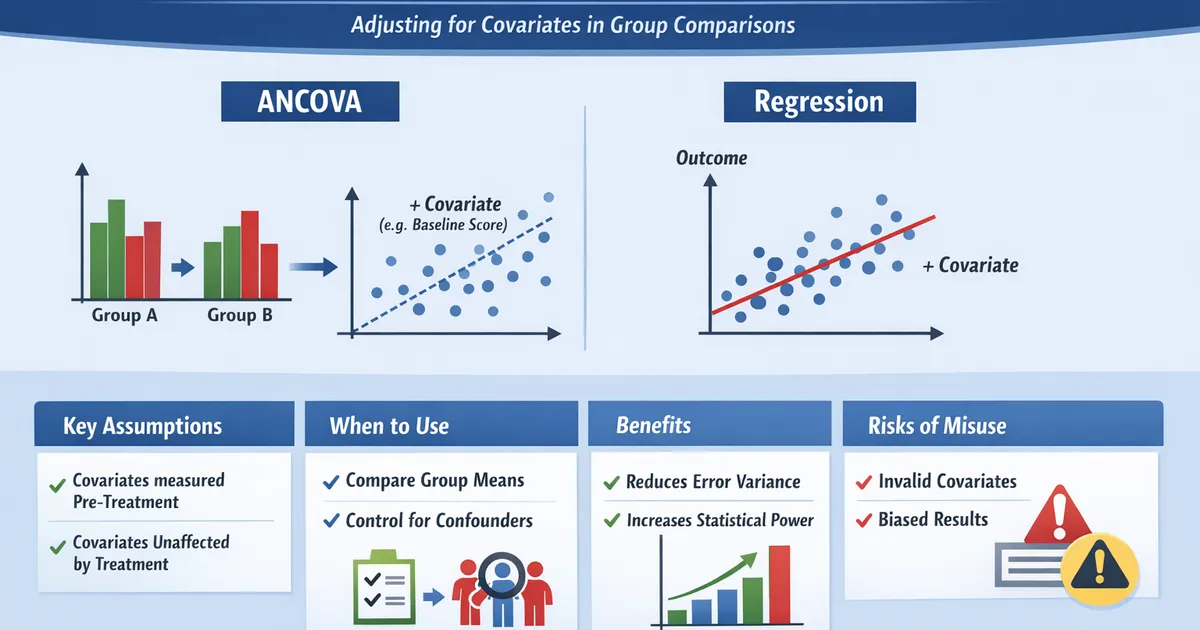
Controlling for Covariates: ANCOVA vs. Regression
When and how to control for covariates in group comparisons. Covers ANCOVA, regression adjustment, and the key assumptions that make covariate adjustment valid.
