Contents
Pre-Registration Lite for Product Experiments: A Pragmatic Workflow
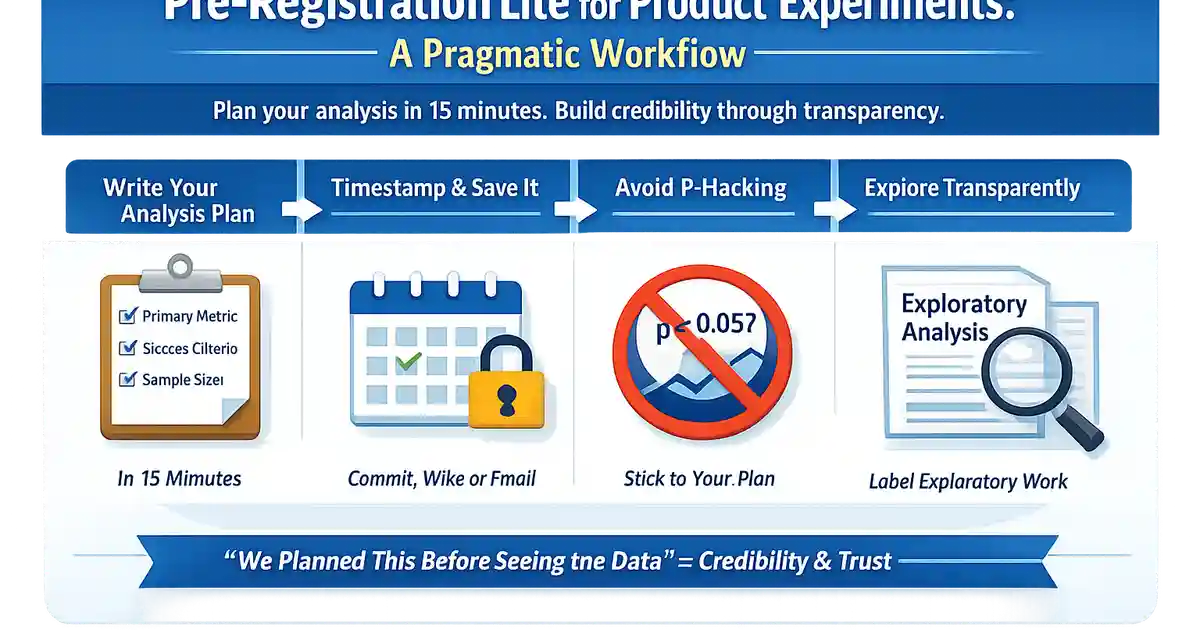
A lightweight pre-registration process that works in fast-moving product teams. Document your analysis plan in 15 minutes and build credibility through transparency.
Quick Hits
- •Pre-registration = writing your analysis plan before seeing results
- •Takes 15 minutes; saves hours of defending your methodology later
- •Lock it with a timestamp: commit to git, save in wiki with date, email to yourself
- •You can still do exploratory analysis—just label it honestly
- •Builds credibility over time: 'I planned this before I knew the answer'
TL;DR
Pre-registration means writing your analysis plan before seeing results—it prevents p-hacking, builds credibility, and takes only 15 minutes with this lite approach. Document your primary metric, success criteria, and analysis timing. Timestamp it (git commit, wiki save, email). You can still explore; just label exploratory findings honestly. The payoff: "This was our plan before we saw any data."
Why Pre-Registration Matters
The Problem It Solves
Without Pre-Registration:
─────────────────────────
Analyst: "Conversion increased 4%!"
Skeptic: "Did you check other metrics first?"
Analyst: "..."
Skeptic: "Did you decide on the analysis after seeing the data?"
Analyst: "..."
Skeptic: "How do we know you didn't try 10 approaches?"
Analyst: "Trust me?"
Skeptic: "..."
With Pre-Registration:
──────────────────────
Analyst: "Conversion increased 4%!"
Skeptic: "Did you—"
Analyst: "Here's our pre-analysis plan from two weeks ago."
[Shows timestamped document]
Skeptic: "Okay, let's discuss the results."
What Pre-Registration Provides
| Without | With |
|---|---|
| "I promise I didn't p-hack" | Timestamped proof |
| Defending methodology after | Methodology locked before |
| "Just trust me" | "Check the commit" |
| Post-hoc suspicion | Pre-hoc credibility |
The 15-Minute Template
Minimum Viable Pre-Registration
# Pre-Analysis Plan: [Experiment Name]
**Date Written**: [Date, before looking at results]
**Experiment Start**: [Date]
**Planned Analysis Date**: [Date]
**Author**: [Your name]
---
## Primary Metric
**Metric**: [Name, e.g., Purchase Conversion Rate]
**Definition**:
- Numerator: [What counts as success]
- Denominator: [What's the population]
- Attribution window: [How long after exposure]
---
## Decision Rule
**Ship if**: [Primary metric CI lower bound > 0 AND no guardrail violations]
**Don't ship if**: [CI upper bound < 0 OR guardrail violation]
**Inconclusive if**: [CI includes 0 and MDE]
---
## Sample & Timing
**Target sample**: [N per group or duration]
**Minimum to analyze**: [If using sequential]
**Analysis timing**: [When you'll pull data]
---
## Guardrails
- [Metric 1]: Should not decrease more than [X%]
- [Metric 2]: Should not increase more than [Y]
---
## Segments (Pre-specified, Exploratory)
- New vs Returning users
- Mobile vs Desktop
*Note: Segment analyses are exploratory; interaction tests required*
---
## Timestamp
Committed to git / Saved to wiki / Emailed to self at: [TIME/DATE]
How to Timestamp
Option 1: Git Commit
git add experiments/checkout_v2/pre_analysis_plan.md
git commit -m "Pre-analysis plan for checkout v2 experiment"
# Commit hash and timestamp are now immutable proof
Option 2: Wiki with Version History
1. Create page in Confluence/Notion/Wiki
2. Save (system records timestamp)
3. Link to page in experiment config
4. Version history proves the date
Option 3: Email to Yourself
1. Write plan in doc
2. Email to yourself (and cc stakeholders)
3. Email timestamp serves as proof
Option 4: Internal Pre-Reg System
If your experimentation platform supports it, use it.
The timestamp is automatic and visible to all.
Detailed Templates by Experiment Type
A/B Test: Conversion Metric
# Pre-Analysis Plan: Checkout Flow v2
**Written**: 2026-01-15, before experiment launch
**Experiment Period**: 2026-01-16 to 2026-01-30
**Analysis Date**: 2026-01-31
## Hypothesis
The simplified checkout flow will increase purchase conversion by reducing friction.
## Primary Metric
**Metric**: Purchase Conversion Rate
- **Numerator**: Users who completed at least one purchase
- **Denominator**: Users assigned to experiment who reached checkout
- **Window**: 7 days from first exposure
## Sample Size
- **Required**: 50,000 users per group (based on 80% power for 2% MDE)
- **Duration**: Run until powered or 14 days max
## Analysis
- **Test**: Two-proportion z-test, two-tailed
- **$\alpha$**: 0.05
- **Pre-specified MDE**: 2% relative lift
## Decision Rule
- **Ship**: CI lower bound > 0 AND no guardrail violations
- **Don't ship**: CI upper bound < 0 OR guardrail violation
- **Extend/Review**: CI includes 0
## Guardrails
1. Revenue per user: Should not decrease > 5%
2. Checkout errors: Should not increase > 10%
3. Support tickets: Should not increase > 20%
## Secondary Metrics (Exploratory)
- Add-to-cart rate
- Time to purchase
- Cart abandonment rate
## Segments (Exploratory)
- New vs Returning
- Mobile vs Desktop
- Geography (US, EU, ROW)
Segment analyses require interaction tests before claiming differential effects.
## Exclusions
- Bot traffic (defined by existing bot filter)
- Internal employees (email @company.com)
- Users assigned < 1 hour (contamination buffer)
---
Committed: git commit abc123, 2026-01-15 14:32 UTC
A/B Test: Continuous Metric (Revenue)
# Pre-Analysis Plan: Upsell Banner
**Written**: 2026-01-20
**Experiment**: 2026-01-21 to 2026-02-04
## Primary Metric
**Metric**: Revenue Per User (RPU)
- **Definition**: Sum of transaction_amount / count of users
- **Users with $0**: Included (contribute $0 to numerator)
- **Window**: 14 days from assignment
## Sample Size
- **Required**: 30,000 per group (80% power for 5% lift in RPU)
- **Variance estimate**: Based on last 30 days RPU distribution
## Analysis
- **Test**: Welch's t-test
- **Confidence interval**: Bootstrap BCa (10,000 iterations)
- **$\alpha$**: 0.05
## Outlier Handling
- **Winsorization**: 99th percentile ($847 based on historical)
- **Sensitivity**: Report both winsorized and non-winsorized
## Decision Rule
- **Ship**: CI lower bound > 0 AND point estimate > $0.50/user
- **Don't ship**: CI upper bound < 0
- **Judgment call**: Positive but < $0.50/user
## Guardrails
- Conversion rate should not decrease > 2%
- Error rate should not increase > 5%
---
Committed: 2026-01-20 09:45 UTC
Model Evaluation
# Pre-Analysis Plan: Classifier v2 Evaluation
**Written**: 2026-01-18
**Eval Dataset**: eval_set_v3 (created 2026-01-10)
## Models
- **Baseline**: classifier_v1 (current production)
- **Candidate**: classifier_v2 (retrained with new features)
## Primary Metric
**Metric**: AUC-ROC
- **Computation**: sklearn.metrics.roc_auc_score
- **Ground truth**: Majority vote of 3 human raters
## Sample
- **Eval set size**: 2,500 examples
- **Class balance**: 20% positive (matches production)
## Analysis
- **Test**: DeLong's test for correlated AUCs
- **$\alpha$**: 0.05
- **CI**: Bootstrap paired, 2,000 iterations
## Decision Rule
- **Deploy v2 if**: AUC improvement significant AND > 0.01 absolute
- **Keep v1 if**: No significant improvement OR regression
- **Further evaluation if**: Significant but < 0.01
## Secondary Metrics
- Precision at 90% recall
- F1 at optimal threshold
- Calibration (Brier score)
---
Documented: 2026-01-18
Handling Deviations
When Deviations Are Okay
You can deviate from your pre-analysis plan. The key is documentation:
## Deviations from Pre-Analysis Plan
### Deviation 1: Extended experiment duration
- **Original**: 14 days
- **Actual**: 18 days
- **Reason**: Holiday weekend caused abnormal traffic; extended for representative sample
- **Impact**: Larger sample; more precise estimates
### Deviation 2: Changed outlier threshold
- **Original**: Winsorize at 99th percentile
- **Actual**: Winsorize at 97th percentile
- **Reason**: 99th percentile was $12,000 due to one enterprise order discovered during data quality check
- **Impact**: Ran sensitivity analysis with both; results consistent
### Deviation 3: Added post-hoc segment analysis
- **Original**: Overall analysis only
- **Actual**: Added mobile vs desktop breakdown
- **Reason**: Stakeholder request after overall result was flat
- **Status**: Labeled as EXPLORATORY in results
### No Changes
- Primary metric definition: As planned
- Decision rule: As planned
- Statistical test: As planned
When Deviations Are Red Flags
These should rarely happen without strong justification:
| Deviation | Red Flag Level | Acceptable If |
|---|---|---|
| Change primary metric | 🔴 High | Major data quality issue discovered |
| Change test after seeing data | 🔴 High | Original test assumptions violated |
| Remove data after seeing results | 🔴 High | Documented quality issue (not outlier removal) |
| Change success threshold | 🟡 Medium | Business context changed |
| Add exploratory analyses | 🟢 Low | Labeled as exploratory |
Integration with Experiment Workflow
Where Pre-Registration Fits
EXPERIMENT LIFECYCLE
────────────────────
1. DESIGN
└─ Define hypothesis, metrics, sample size
2. PRE-REGISTRATION ← Lock the plan here
└─ Write and timestamp analysis plan
3. LAUNCH
└─ Start experiment, begin data collection
4. MONITORING
└─ Check for bugs, SRM, data quality
└─ DO NOT look at treatment effects
5. ANALYSIS
└─ Pull data according to pre-registered plan
└─ Run pre-specified analyses
└─ Run exploratory analyses (labeled)
6. REPORTING
└─ Report all pre-specified analyses
└─ Report exploratory with caveats
└─ Link to pre-registration
Automation Ideas
def create_prereg_from_config(experiment_config):
"""
Generate pre-registration document from experiment config.
"""
prereg = f"""
# Pre-Analysis Plan: {experiment_config['name']}
**Auto-generated**: {experiment_config['created_date']}
**Experiment Start**: {experiment_config['start_date']}
## Primary Metric
**Metric**: {experiment_config['primary_metric']['name']}
- **Definition**: {experiment_config['primary_metric']['definition']}
## Sample Size
- **Target**: {experiment_config['sample_size']} per group
- **Duration**: {experiment_config['duration_days']} days
## Decision Rule
- **MDE**: {experiment_config['mde']}
- **Ship if**: Lower CI bound > 0
- **α**: {experiment_config.get('alpha', 0.05)}
## Guardrails
"""
for guardrail in experiment_config.get('guardrails', []):
prereg += f"- {guardrail['metric']}: {guardrail['threshold']}\n"
return prereg
# Example usage
config = {
'name': 'Checkout v3',
'created_date': '2026-01-26',
'start_date': '2026-01-27',
'primary_metric': {
'name': 'Conversion Rate',
'definition': 'Purchases / Unique Users'
},
'sample_size': 50000,
'duration_days': 14,
'mde': 0.02,
'guardrails': [
{'metric': 'Revenue', 'threshold': 'No decrease > 5%'},
{'metric': 'Errors', 'threshold': 'No increase > 10%'}
]
}
print(create_prereg_from_config(config))
Common Objections and Responses
"We move too fast for this"
Response: The lite version takes 15 minutes. You probably spend more time defending methodology in review. Pre-registration prevents those debates.
"What if our hypothesis changes?"
Response: Document it. "Original hypothesis was X. After [learning/discussion], we refined to Y before analysis." Iteration before analysis is fine—changing after is the problem.
"This feels like bureaucracy"
Response: It's insurance, not bureaucracy. One sentence each for: metric, decision rule, timing. That's it for minimum viable pre-reg.
"I already know I won't p-hack"
Response: I believe you. But your stakeholders don't know that. Pre-registration lets you prove it rather than just assert it.
"What if the pre-specified analysis is wrong?"
Response: Do the better analysis too! Report: "Our pre-specified approach was X [with results]. We also conducted [better approach] which showed [results]. We recommend focusing on [better approach] because [reason]."
Building the Habit
Week 1-2: Minimum Viable
Before analyzing any experiment:
1. Write one sentence: "Primary metric is [X]"
2. Write one sentence: "Ship if [condition]"
3. Email it to yourself
Done. That's pre-registration.
Week 3-4: Add Structure
Use the 15-minute template:
- Primary metric with definition
- Decision rule
- Sample size/timing
- Guardrails
Week 5+: Full Workflow
- Integrate with experiment launch process
- Auto-generate from config
- Store in central repository
- Link in all analysis docs
R Implementation
# Function to create pre-registration document
create_prereg <- function(
experiment_name,
primary_metric,
metric_definition,
sample_size,
duration_days,
mde,
guardrails = NULL,
alpha = 0.05
) {
prereg <- paste0(
"# Pre-Analysis Plan: ", experiment_name, "\n\n",
"**Date**: ", Sys.Date(), "\n\n",
"## Primary Metric\n",
"**Metric**: ", primary_metric, "\n",
"**Definition**: ", metric_definition, "\n\n",
"## Sample\n",
"- Target: ", format(sample_size, big.mark = ","), " per group\n",
"- Duration: ", duration_days, " days\n\n",
"## Decision Rule\n",
"- MDE: ", mde * 100, "%\n",
"- α: ", alpha, "\n",
"- Ship if: CI lower bound > 0\n\n"
)
if (!is.null(guardrails)) {
prereg <- paste0(prereg, "## Guardrails\n")
for (g in guardrails) {
prereg <- paste0(prereg, "- ", g, "\n")
}
}
prereg <- paste0(prereg, "\n---\nGenerated: ", Sys.time())
return(prereg)
}
# Example
prereg_doc <- create_prereg(
experiment_name = "New Checkout Flow",
primary_metric = "Conversion Rate",
metric_definition = "Purchases / Sessions with checkout",
sample_size = 50000,
duration_days = 14,
mde = 0.02,
guardrails = c("Revenue: no decrease > 5%", "Errors: no increase > 10%")
)
cat(prereg_doc)
Related Articles
- Analytics Reporting (Pillar) - Complete reporting guide
- Common Analyst Mistakes - What pre-registration prevents
- Writing Methods Sections - Documentation practices
- When to Say Inconclusive - Decision rules
Key Takeaway
Pre-registration isn't bureaucracy—it's insurance against accusations of p-hacking and post-hoc storytelling. The lite version takes 15 minutes: write down your primary metric and how you'll define it, your decision rule (when you'll ship vs not ship), and when you'll analyze. Timestamp it with a git commit, wiki save, or email. When you present results, you can honestly say "this was our plan before we saw any data." That credibility is worth far more than the time investment. You can still explore the data—just label exploratory findings honestly and acknowledge they need replication.
References
- https://doi.org/10.1073/pnas.1708274114
- https://doi.org/10.1177/2515245918770963
- https://www.microsoft.com/en-us/research/publication/top-challenges-from-the-first-practical-online-controlled-experiments-summit/
- Nosek, B. A., Ebersole, C. R., DeHaven, A. C., & Mellor, D. T. (2018). The preregistration revolution. *Proceedings of the National Academy of Sciences*, 115(11), 2600-2606.
- Nosek, B. A., et al. (2019). Preregistration is hard, and worthwhile. *Trends in Cognitive Sciences*, 23(10), 815-818.
- Kohavi, R., Tang, D., & Xu, Y. (2020). *Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing*. Cambridge University Press.
Frequently Asked Questions
Isn't this overkill for product experiments?
What if I need to change my analysis after seeing data?
What's the minimum I need to pre-specify?
Key Takeaway
Pre-registration isn't bureaucracy—it's insurance against accusations of p-hacking and post-hoc storytelling. The lite version takes 15 minutes: write down your primary metric, how you'll define success, and when you'll analyze. Timestamp it. When you present results, you can honestly say 'this was our plan before we saw any data.' That credibility is worth far more than the time investment. You can still explore—just label exploratory findings honestly.