Contents
Cohen's Kappa
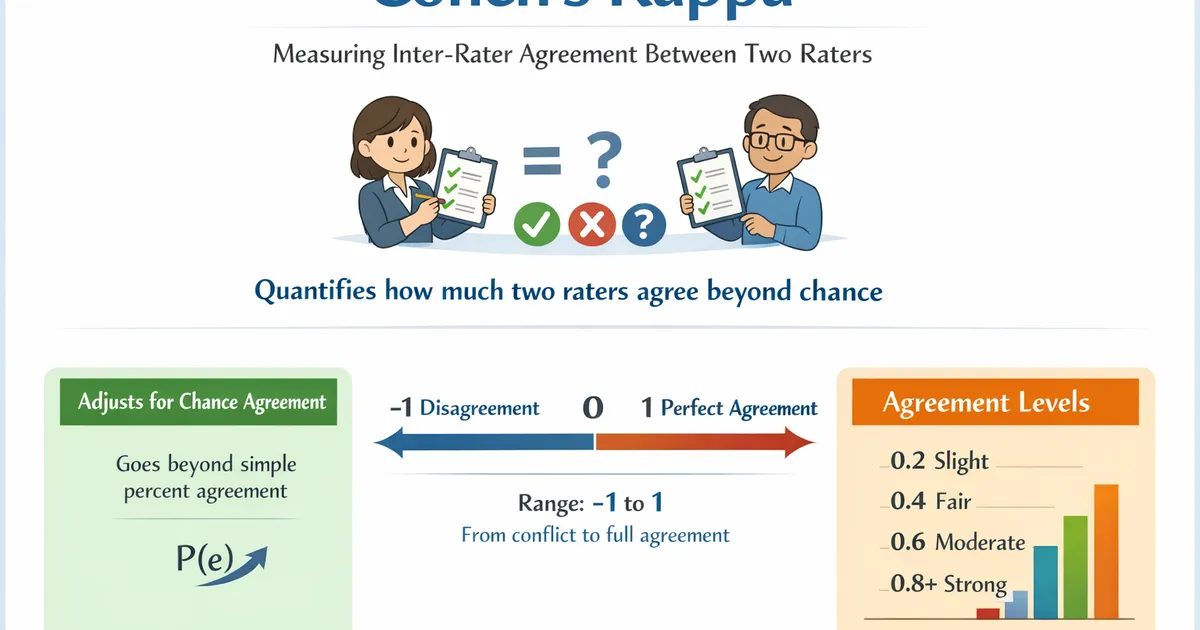
Cohen's Kappa measures inter-rater agreement between two raters classifying items into categories. Use it to quantify how much two raters agree beyond what would be expected by chance.
Quick Hits
- •Measures agreement between exactly two raters on categorical classifications
- •Accounts for agreement expected by chance (unlike simple percent agreement)
- •Ranges from -1 (systematic disagreement) through 0 (chance) to 1 (perfect agreement)
- •Common benchmarks: < 0.2 slight, 0.2-0.4 fair, 0.4-0.6 moderate, 0.6-0.8 substantial, 0.8-1.0 near-perfect
- •Requires the same two raters to classify the same set of items
The StatsTest Flow: Relationship or Prediction >> Relationship >> Agreement between raters >> Two raters
Not sure this is the right statistical method? Use the Choose Your StatsTest workflow to select the right method.
What is Cohen's Kappa?
Cohen's Kappa () is a statistic that measures the agreement between two raters who each classify items into mutually exclusive categories. Unlike simple percent agreement, Cohen's kappa accounts for the probability of agreement occurring by chance.
The formula is:
Where is the observed proportion of agreement and is the expected proportion of agreement by chance.
Cohen's Kappa is also called the Kappa Statistic, Kappa Coefficient, or Cohen's Kappa Coefficient.
Assumptions for Cohen's Kappa
The assumptions include:
- Two Raters
- Same Items Rated
- Categorical Outcome
- Mutually Exclusive Categories
- Independent Ratings
Two Raters
Cohen's kappa is defined for exactly two raters. Both raters must classify the same set of items.
If you have three or more raters, use Krippendorff's Alpha or Fleiss' kappa instead.
Same Items Rated
Both raters must rate the same set of items. Missing ratings reduce the effective sample size.
Categorical Outcome
The rating must be categorical. For continuous ratings (e.g., scores on a 0-100 scale), use intraclass correlation (ICC) instead.
Mutually Exclusive Categories
Each item must be classified into exactly one category. Multi-label classifications require alternative approaches.
Independent Ratings
The two raters must make their judgments independently without consulting each other.
When to use Cohen's Kappa?
- Two raters are classifying the same items
- The outcome is categorical (two or more categories)
- You want to measure agreement beyond chance
- Ratings are independent
Common Applications
- Data labeling quality: Do two annotators agree on sentiment labels?
- Content moderation: Do two reviewers agree on policy violation classifications?
- Clinical diagnosis: Do two physicians agree on disease staging?
- Code review: Do two reviewers agree on severity classifications?
For measuring the strength of association between two categorical variables (not rater agreement), use Cramer's V or the Phi Coefficient.
Cohen's Kappa Example
Two content moderators independently classify 200 user posts as "safe," "borderline," or "violation."
| Rater B: Safe | Rater B: Borderline | Rater B: Violation | |
|---|---|---|---|
| Rater A: Safe | 120 | 8 | 2 |
| Rater A: Borderline | 10 | 30 | 5 |
| Rater A: Violation | 1 | 4 | 20 |
Observed agreement: (120 + 30 + 20) / 200 = 85%. Expected chance agreement: 52.5%. Cohen's kappa: = (0.85 - 0.525) / (1 - 0.525) = 0.68.
Interpretation: = 0.68 indicates substantial agreement. The raters agree well beyond what chance would predict, though there is room for improvement on borderline cases. Since the categories are ordinal, a weighted kappa would give partial credit for near-misses (e.g., "safe" vs. "borderline").
References
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3900058/
- https://www.sciencedirect.com/topics/medicine-and-dentistry/cohens-kappa
Frequently Asked Questions
What is the difference between Cohen's kappa and percent agreement?
When should I use weighted kappa?
What if I have more than two raters?
Key Takeaway
Cohen's kappa is the standard measure of agreement between two raters on categorical labels, corrected for chance. It tells you whether your raters are consistently agreeing beyond what you would expect if they were guessing. Use it for quality control in labeling, content moderation, clinical diagnosis, and any task where two people classify the same items.