Contents
Kolmogorov-Smirnov Test
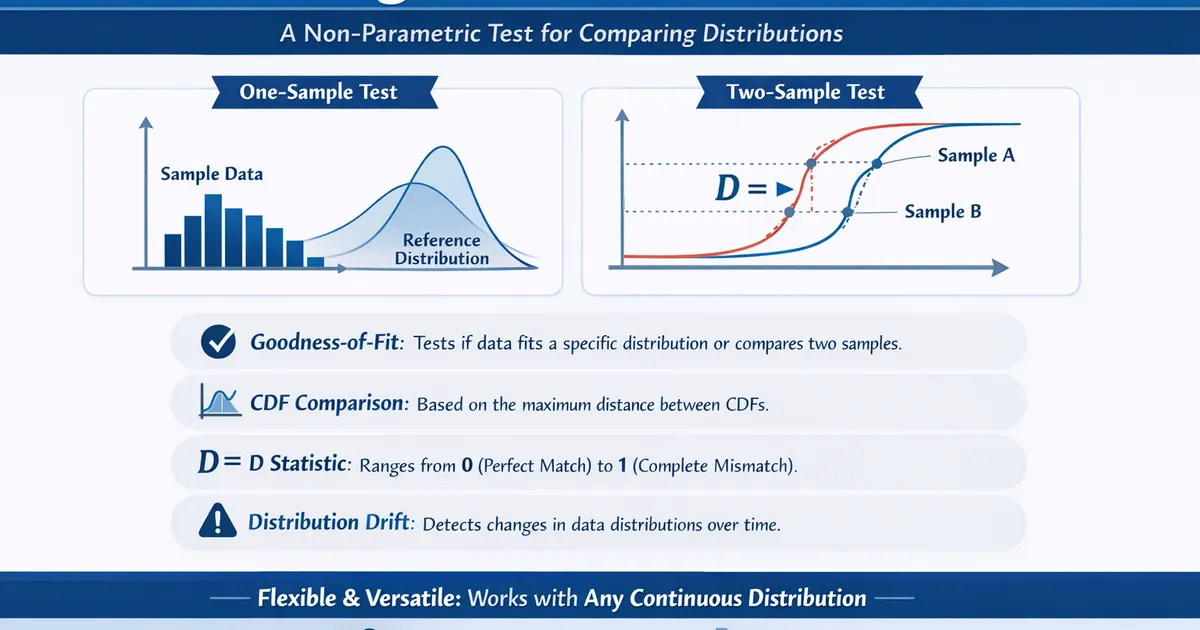
The Kolmogorov-Smirnov Test compares a sample to a reference distribution or compares two samples to each other. Use it to test goodness-of-fit to any continuous distribution or to detect distribution drift.
Quick Hits
- •Tests whether a sample follows a specified distribution (one-sample) or whether two samples come from the same distribution (two-sample)
- •Based on the maximum distance between cumulative distribution functions (CDFs)
- •Non-parametric: works with any continuous distribution
- •D statistic ranges from 0 (perfect match) to 1 (completely different)
- •Less powerful than Shapiro-Wilk for testing normality specifically, but more flexible
The StatsTest Flow: Difference or Goodness of Fit >> Testing Distribution Assumptions >> Does my data follow a specific distribution?
Not sure this is the right statistical method? Use the Choose Your StatsTest workflow to select the right method.
What is the Kolmogorov-Smirnov Test?
The Kolmogorov-Smirnov (KS) Test is a non-parametric test that compares cumulative distribution functions (CDFs). It comes in two variants:
- One-sample KS test: Compares a sample's empirical CDF to a theoretical reference CDF (e.g., normal, uniform, exponential).
- Two-sample KS test: Compares the empirical CDFs of two independent samples to test whether they come from the same distribution.
The test statistic, D, is the maximum absolute difference between the two CDFs being compared. Larger values of D indicate greater departure from the null hypothesis.
The Kolmogorov-Smirnov Test is also called the KS Test, the Kolmogorov Test, or the Smirnov Test (two-sample version).
Assumptions for the Kolmogorov-Smirnov Test
The assumptions include:
- Continuous Data
- Independent Observations
- Fully Specified Reference Distribution (one-sample version)
Continuous Data
The KS test is designed for continuous distributions. For discrete data, the test is conservative (p-values are too large). Use the Chi-Square Goodness of Fit Test for categorical data.
Independent Observations
Each observation must be independent. Time-series data or clustered observations violate this assumption.
Fully Specified Reference Distribution
For the one-sample test, the reference distribution must be completely specified in advance, including all parameters. If you estimate the mean and variance from the data and then test normality against that fitted normal, the p-values will be too large. Use the Lilliefors correction or the Shapiro-Wilk Test instead.
When to use the Kolmogorov-Smirnov Test?
- You want to test whether your data follows a specific continuous distribution (normal, exponential, uniform, etc.)
- You want to compare two samples to see if they come from the same distribution
- You need a non-parametric, distribution-free approach
- You are monitoring for distribution drift over time
For normality testing specifically, the Shapiro-Wilk Test is more powerful. For comparing variances between groups, use Levene's Test.
Kolmogorov-Smirnov Test Example
Application: Monitoring model input feature distribution drift.
You deployed a machine learning model trained on data from Q3 2025. In Q1 2026, you want to check whether the distribution of the key input feature (user engagement score) has shifted.
You run a two-sample KS test comparing the Q3 2025 training distribution to the Q1 2026 production distribution. D = 0.15, p = 0.003. The significant p-value indicates the distributions have shifted, suggesting potential model degradation. You investigate and discover a UI change that increased engagement scores across the board.
References
- https://www.itl.nist.gov/div898/handbook/eda/section3/eda35g.htm
- https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test
Frequently Asked Questions
When should I use the KS test instead of the Shapiro-Wilk test?
What is the two-sample KS test used for?
What are the limitations of the KS test?
Key Takeaway
The Kolmogorov-Smirnov test is a versatile non-parametric test for comparing distributions. The one-sample version tests whether data follows any specified continuous distribution. The two-sample version tests whether two samples come from the same distribution. It is especially useful for detecting distribution drift in monitoring and ML pipelines.